In recent few interviews there was a scenario that interviewer asked me to remove duplicate records from SQL Server table.
For example:
There is a table with 3 columns (COL1, COL2, COL3), having duplicate data stored like below screen shot of the table.
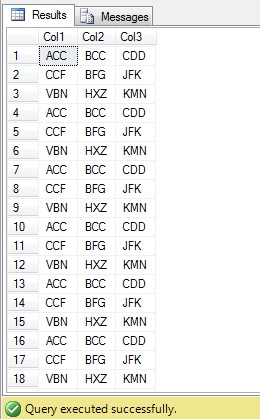
If you can carefully look at the records you can find that there is only 3 set of records, but had duplicates for the same. So how can you remove the duplicates from this table. Tricky isn’t it?
The following is the sample script for creating a TestTable and inserting data to test it on your side.
[sourcecode language=”plain”]
–Create a Sample Table.
CREATE TABLE TestTable ( Col1 VarChar(50), Col2 VarChar(50), Col3 VarChar(50))
–Inserting Test Data
INSERT INTO TestTable VALUES ('ACC','BCC','CDD')
INSERT INTO TestTable VALUES ('CCF','BFG','JFK')
INSERT INTO TestTable VALUES ('VBN','HXZ','KMN')
–Inserting Duplicate Records of the above (10 Copies)
Declare @Counter int
SET @Counter =0;
While( @Counter < 10)
BEGIN
INSERT INTO TestTable VALUES ('ACC','BCC','CDD')
INSERT INTO TestTable VALUES ('CCF','BFG','JFK')
INSERT INTO TestTable VALUES ('VBN','HXZ','KMN')
SET @Counter = @Counter + 1
END
–Verify Inserted Content
SELECT * from TestTable
[/sourcecode]
We need to remove duplicate records from this table now. With minimal effort.
If there was a primary key column with unique value (identity field), would have been easy for us to remove duplicates.
In this scenario, we have no primary key or to uniquely identify the records.
In normal case if we have an IDENTITY column in the table we could be able to delete like this
DELETE FROM [TESTDEMO] WHERE DEMOID NOT IN (SELECT MIN(DEMOID) FROM [TESTDEMO] GROUP BY [DEMONAME])
an easy way to remove duplicates, if we have an identity column.
But in my above scenario, it’s not possible. But it’s possible with my following query, less effort.
I will explain the query later, for now you can evaluate the query.
[sourcecode language=”plain”]
— I am using Common Table Expressions(CTE) here, so that i can generate a unique id temporarily for each Record
— and reference it later for removal. CTE actually has the reference to the original record from [TestTable],
— so when we delete a record from CTE, it will delete the associated record from [TestTable] table also.
— Quiet efficient way, some of my friends argued , what is the difference in having CTE and using a Temporary Table.
— CTE is not actually temporary table, a temporary result se, whose scope is until the query execution is over. (More given below)
— (More details given below, at the end of the post)
WITH MyTestTable AS
(
SELECT Col1,Col2,Col3, ROW_NUMBER() OVER(order by Col1,Col2,Col3 ASC) as ROW_ID from TestTable
)
–SELECT * from MyTestTable
–SELECT MIN(ROW_ID) as ROWID,Col1,Col2,COL3 FROM MyTestTable GROUP BY Col1,Col2,COL3
DELETE from myTestTable where ROW_ID NOT IN ( SELECT MIN(ROW_ID) FROM myTestTable GROUP BY Col1,Col2,COL3 )
SELECT * from [TESTTABLE]
[/sourcecode]
The above query has successfully removed duplicates from the [TestTable] and the result is
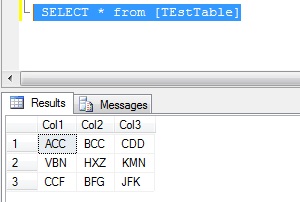
Query Explanation
- First thing i done was taking all the records to a CTE and assign a unique identifier to each record, here for easiest i could say it’s ROW_NUMBER() function who generated for me based on order by Col1,Col2,Col3 ASC.
A sample query for test the result is
[sourcecode language=”plain”]
WITH MyTestTable AS
(
SELECT Col1,Col2,Col3, ROW_NUMBER() OVER(order by Col1,Col2,Col3 ASC) as ROW_ID from TestTable
)SELECT * from MyTestTable
[/sourcecode]
and will give your the result as like below.
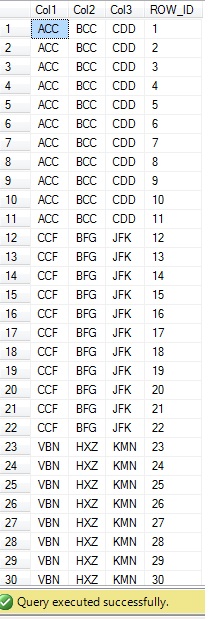
-
Now take Min(ROW_ID) for each group of similar/duplicate records. Why i am taking MIN is, we are going to keep only the least one. If in real time if you have a MODIFIED_DATE or CREATE_DATE column in your table, Would be much more easier using MIN(MODIFIED_DATE), defenitly i should have some thing to Group it.
You can test the sample query like this
[sourcecode language=”plain”]
SELECT MIN(ROW_ID) as ROWID,Col1,Col2,COL3 FROM MyTestTable GROUP BY Col1,Col2,COL3
[/sourcecode]
which would fetch your result like below
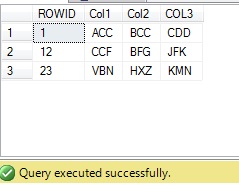
- Now i formulated a Delete query like this, which will delete all records except the min(ROW_ID) one. So only the records fectched in the STEP:2 query will be remained in the [TESTTABLE] and remaining will be deleted.
[sourcecode language=”plain”]
DELETE from myTestTable where ROW_ID NOT IN ( SELECT MIN(ROW_ID) FROM myTestTable GROUP BY Col1,Col2,COL3 )
[/sourcecode]
- The Final Query is
[sourcecode language=”plain”]
WITH MyTestTable AS
(
SELECT Col1,Col2,Col3, ROW_NUMBER() OVER(order by Col1,Col2,Col3 ASC) as ROW_ID from TestTable
)
DELETE from myTestTable where ROW_ID NOT IN ( SELECT MIN(ROW_ID) FROM myTestTable GROUP BY Col1,Col2,COL3 )
SELECT * from [TESTTABLE]
[/sourcecode]
Result is :
- Kudos!!! The duplicates are removed. Rocking right. I am not saying that it’s the perfect way, i am sure might be there some other perfect queries would be there for this scenario. But i felt this is safe and good for my requirement.
The more on Common Table Expressions
A common table expression (CTE) can be thought of as a temporary result set that is defined within the execution scope of a single SELECT, INSERT, UPDATE, DELETE, or CREATE VIEW statement. A CTE is similar to a derived table in that it is not stored as an object and lasts only for the duration of the query. Unlike a derived table, a CTE can be self-referencing and can be referenced multiple times in the same query.
A CTE can be used to:
• Create a recursive query. For more information, see Recursive Queries Using Common Table Expressions.
• Substitute for a view when the general use of a view is not required; that is, you do not have to store the definition in metadata.
• Enable grouping by a column that is derived from a scalar subselect, or a function that is either not deterministic or has external access.
• Reference the resulting table multiple times in the same statement.
Using a CTE offers the advantages of improved readability and ease in maintenance of complex queries. The query can be divided into separate, simple, logical building blocks. These simple blocks can then be used to build more complex, interim CTEs until the final result set is generated.
CTEs can be defined in user-defined routines, such as functions, stored procedures, triggers, or views.
Discover more from C4: Container, Code, Cloud & Context
Subscribe to get the latest posts sent to your email.