Preparing data for RAG requires specialized ETL pipelines. After building pipelines for 50+ RAG systems, I’ve learned what works. Here’s the complete guide to ETL for vector embeddings.
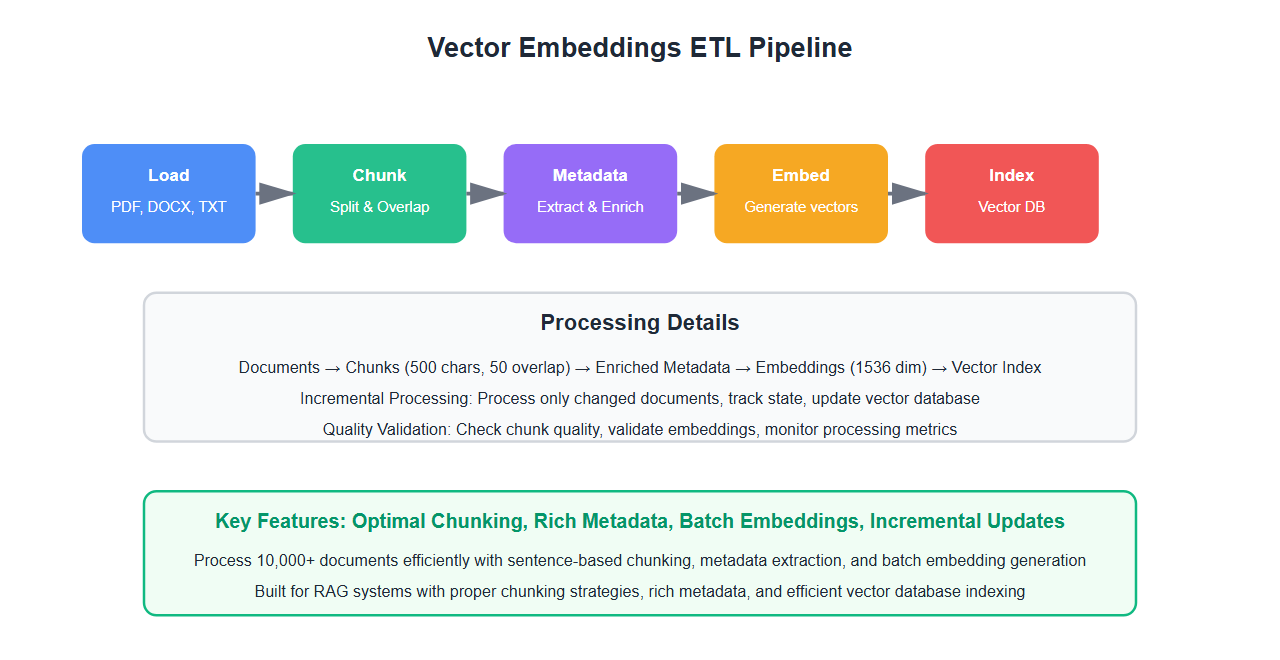
Why Vector Embeddings ETL is Different
RAG systems require specialized data preparation:
- Chunking: Documents must be split into optimal chunks
- Metadata: Rich metadata is essential for retrieval
- Embeddings: Generate embeddings efficiently at scale
- Indexing: Build efficient vector indexes
- Updates: Handle incremental updates gracefully
After building pipelines for multiple RAG systems, I’ve learned that proper ETL is critical for retrieval quality.
Document Processing Pipeline
1. Document Loading
Load documents from various sources:
from typing import List, Dict, Iterator
from pathlib import Path
import json
import re
from dataclasses import dataclass
import numpy as np
class DocumentLoader:
def __init__(self):
self.loaded_documents = []
def load_pdf(self, file_path: str) -> Dict:
# Load PDF document
with open(file_path, 'rb') as f:
pdf_reader = PyPDF2.PdfReader(f)
text = ""
metadata = {
"source": file_path,
"type": "pdf",
"pages": len(pdf_reader.pages)
}
for page_num, page in enumerate(pdf_reader.pages):
text += page.extract_text() + "\n"
return {
"text": text,
"metadata": metadata
}
def load_docx(self, file_path: str) -> Dict:
# Load DOCX document
doc = docx.Document(file_path)
text = "\n".join([para.text for para in doc.paragraphs])
metadata = {
"source": file_path,
"type": "docx"
}
return {
"text": text,
"metadata": metadata
}
def load_text(self, file_path: str) -> Dict:
# Load plain text file
with open(file_path, 'r', encoding='utf-8') as f:
text = f.read()
metadata = {
"source": file_path,
"type": "text"
}
return {
"text": text,
"metadata": metadata
}
def load_from_directory(self, directory: str) -> List[Dict]:
# Load all documents from directory
documents = []
path = Path(directory)
for file_path in path.rglob('*'):
if file_path.suffix == '.pdf':
documents.append(self.load_pdf(str(file_path)))
elif file_path.suffix == '.docx':
documents.append(self.load_docx(str(file_path)))
elif file_path.suffix == '.txt':
documents.append(self.load_text(str(file_path)))
return documents
# Usage
loader = DocumentLoader()
documents = loader.load_from_directory("documents/")
2. Text Chunking
Split documents into optimal chunks:
from typing import List, Dict
import re
from dataclasses import dataclass
@dataclass
class Chunk:
text: str
metadata: Dict
chunk_id: str
start_index: int
end_index: int
class TextChunker:
def __init__(self, chunk_size: int = 500, chunk_overlap: int = 50):
self.chunk_size = chunk_size
self.chunk_overlap = chunk_overlap
def chunk_by_characters(self, text: str, metadata: Dict) -> List[Chunk]:
# Simple character-based chunking
chunks = []
start = 0
chunk_id = 0
while start < len(text):
end = min(start + self.chunk_size, len(text))
chunk_text = text[start:end]
# Try to break at sentence boundary
if end < len(text):
# Look for sentence ending
sentence_end = max(
chunk_text.rfind('.'),
chunk_text.rfind('!'),
chunk_text.rfind('?')
)
if sentence_end > self.chunk_size * 0.5: # If found in second half
end = start + sentence_end + 1
chunk_text = text[start:end]
chunk = Chunk(
text=chunk_text.strip(),
metadata={**metadata, "chunk_index": chunk_id},
chunk_id=f"{metadata.get('source', 'doc')}_{chunk_id}",
start_index=start,
end_index=end
)
chunks.append(chunk)
# Move start with overlap
start = end - self.chunk_overlap
chunk_id += 1
return chunks
def chunk_by_sentences(self, text: str, metadata: Dict) -> List[Chunk]:
# Chunk by sentences
sentences = re.split(r'[.!?]+\s+', text)
chunks = []
current_chunk = []
current_length = 0
chunk_id = 0
for sentence in sentences:
sentence_length = len(sentence)
if current_length + sentence_length > self.chunk_size and current_chunk:
# Create chunk
chunk_text = ' '.join(current_chunk)
chunk = Chunk(
text=chunk_text,
metadata={**metadata, "chunk_index": chunk_id},
chunk_id=f"{metadata.get('source', 'doc')}_{chunk_id}",
start_index=0, # Would need to track actual positions
end_index=len(chunk_text)
)
chunks.append(chunk)
# Keep overlap
overlap_sentences = current_chunk[-2:] if len(current_chunk) >= 2 else current_chunk
current_chunk = overlap_sentences + [sentence]
current_length = sum(len(s) for s in current_chunk)
chunk_id += 1
else:
current_chunk.append(sentence)
current_length += sentence_length
# Add remaining chunk
if current_chunk:
chunk_text = ' '.join(current_chunk)
chunk = Chunk(
text=chunk_text,
metadata={**metadata, "chunk_index": chunk_id},
chunk_id=f"{metadata.get('source', 'doc')}_{chunk_id}",
start_index=0,
end_index=len(chunk_text)
)
chunks.append(chunk)
return chunks
def chunk_by_paragraphs(self, text: str, metadata: Dict) -> List[Chunk]:
# Chunk by paragraphs
paragraphs = text.split('\n\n')
chunks = []
current_chunk = []
current_length = 0
chunk_id = 0
for para in paragraphs:
para_length = len(para)
if current_length + para_length > self.chunk_size and current_chunk:
chunk_text = '\n\n'.join(current_chunk)
chunk = Chunk(
text=chunk_text,
metadata={**metadata, "chunk_index": chunk_id},
chunk_id=f"{metadata.get('source', 'doc')}_{chunk_id}",
start_index=0,
end_index=len(chunk_text)
)
chunks.append(chunk)
current_chunk = [para]
current_length = para_length
chunk_id += 1
else:
current_chunk.append(para)
current_length += para_length
if current_chunk:
chunk_text = '\n\n'.join(current_chunk)
chunk = Chunk(
text=chunk_text,
metadata={**metadata, "chunk_index": chunk_id},
chunk_id=f"{metadata.get('source', 'doc')}_{chunk_id}",
start_index=0,
end_index=len(chunk_text)
)
chunks.append(chunk)
return chunks
# Usage
chunker = TextChunker(chunk_size=500, chunk_overlap=50)
chunks = chunker.chunk_by_sentences(document["text"], document["metadata"])
3. Metadata Extraction
Extract rich metadata for retrieval:
from typing import Dict, List
import re
from datetime import datetime
class MetadataExtractor:
def __init__(self):
self.extracted_metadata = {}
def extract_entities(self, text: str) -> List[str]:
# Extract named entities (simplified)
# In production, use spaCy or similar
entities = []
# Extract dates
date_pattern = r'\d{1,2}/\d{1,2}/\d{4}|\d{4}-\d{2}-\d{2}'
dates = re.findall(date_pattern, text)
entities.extend(dates)
# Extract email addresses
email_pattern = r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b'
emails = re.findall(email_pattern, text)
entities.extend(emails)
return entities
def extract_keywords(self, text: str, top_n: int = 10) -> List[str]:
# Extract keywords (simplified TF-IDF)
words = re.findall(r'\b\w+\b', text.lower())
# Remove stop words (simplified list)
stop_words = {'the', 'a', 'an', 'and', 'or', 'but', 'in', 'on', 'at', 'to', 'for', 'of', 'with', 'by'}
words = [w for w in words if w not in stop_words and len(w) > 3]
# Count frequencies
word_freq = {}
for word in words:
word_freq[word] = word_freq.get(word, 0) + 1
# Get top keywords
sorted_words = sorted(word_freq.items(), key=lambda x: x[1], reverse=True)
return [word for word, freq in sorted_words[:top_n]]
def extract_summary(self, text: str, max_sentences: int = 3) -> str:
# Extract summary (first few sentences)
sentences = re.split(r'[.!?]+\s+', text)
summary = '. '.join(sentences[:max_sentences])
if summary and not summary.endswith('.'):
summary += '.'
return summary
def enrich_metadata(self, chunk: Chunk, document_metadata: Dict) -> Dict:
# Enrich chunk metadata
enriched = {
**chunk.metadata,
**document_metadata,
"entities": self.extract_entities(chunk.text),
"keywords": self.extract_keywords(chunk.text),
"summary": self.extract_summary(chunk.text),
"length": len(chunk.text),
"word_count": len(chunk.text.split())
}
return enriched
# Usage
extractor = MetadataExtractor()
enriched_chunks = []
for chunk in chunks:
enriched_metadata = extractor.enrich_metadata(chunk, document["metadata"])
enriched_chunks.append(Chunk(
text=chunk.text,
metadata=enriched_metadata,
chunk_id=chunk.chunk_id,
start_index=chunk.start_index,
end_index=chunk.end_index
))
4. Embedding Generation
Generate embeddings efficiently:
from typing import List, Dict
import numpy as np
from openai import OpenAI
class EmbeddingGenerator:
def __init__(self, model: str = "text-embedding-3-small", api_key: str = None):
self.model = model
self.client = OpenAI(api_key=api_key) if api_key else None
self.embedding_cache = {}
def generate_embedding(self, text: str) -> List[float]:
# Generate embedding for text
if text in self.embedding_cache:
return self.embedding_cache[text]
if self.client:
response = self.client.embeddings.create(
model=self.model,
input=text
)
embedding = response.data[0].embedding
else:
# Fallback: random embedding for demo
embedding = np.random.rand(1536).tolist()
self.embedding_cache[text] = embedding
return embedding
def generate_batch(self, texts: List[str], batch_size: int = 100) -> List[List[float]]:
# Generate embeddings in batches
embeddings = []
for i in range(0, len(texts), batch_size):
batch = texts[i:i + batch_size]
batch_embeddings = [self.generate_embedding(text) for text in batch]
embeddings.extend(batch_embeddings)
return embeddings
def generate_for_chunks(self, chunks: List[Chunk]) -> List[Dict]:
# Generate embeddings for all chunks
texts = [chunk.text for chunk in chunks]
embeddings = self.generate_batch(texts)
result = []
for chunk, embedding in zip(chunks, embeddings):
result.append({
"chunk_id": chunk.chunk_id,
"text": chunk.text,
"embedding": embedding,
"metadata": chunk.metadata
})
return result
# Usage
embedding_gen = EmbeddingGenerator(model="text-embedding-3-small")
embedded_chunks = embedding_gen.generate_for_chunks(enriched_chunks)
5. Vector Database Loading
Load embeddings into vector database:
from typing import List, Dict
from pinecone import Pinecone, ServerlessSpec
class VectorDatabaseLoader:
def __init__(self, api_key: str, index_name: str):
self.pc = Pinecone(api_key=api_key)
self.index = self.pc.Index(index_name)
def upsert_chunks(self, embedded_chunks: List[Dict], batch_size: int = 100):
# Upsert chunks to vector database
vectors = []
for chunk in embedded_chunks:
vector = {
"id": chunk["chunk_id"],
"values": chunk["embedding"],
"metadata": {
"text": chunk["text"][:1000], # Truncate for metadata
**chunk["metadata"]
}
}
vectors.append(vector)
# Batch upsert
if len(vectors) >= batch_size:
self.index.upsert(vectors=vectors)
vectors = []
# Upsert remaining
if vectors:
self.index.upsert(vectors=vectors)
def update_metadata(self, chunk_id: str, metadata: Dict):
# Update metadata for existing chunk
self.index.update(id=chunk_id, set_metadata=metadata)
def delete_chunks(self, chunk_ids: List[str]):
# Delete chunks from vector database
self.index.delete(ids=chunk_ids)
# Usage
loader = VectorDatabaseLoader(api_key="your-api-key", index_name="rag-index")
loader.upsert_chunks(embedded_chunks)
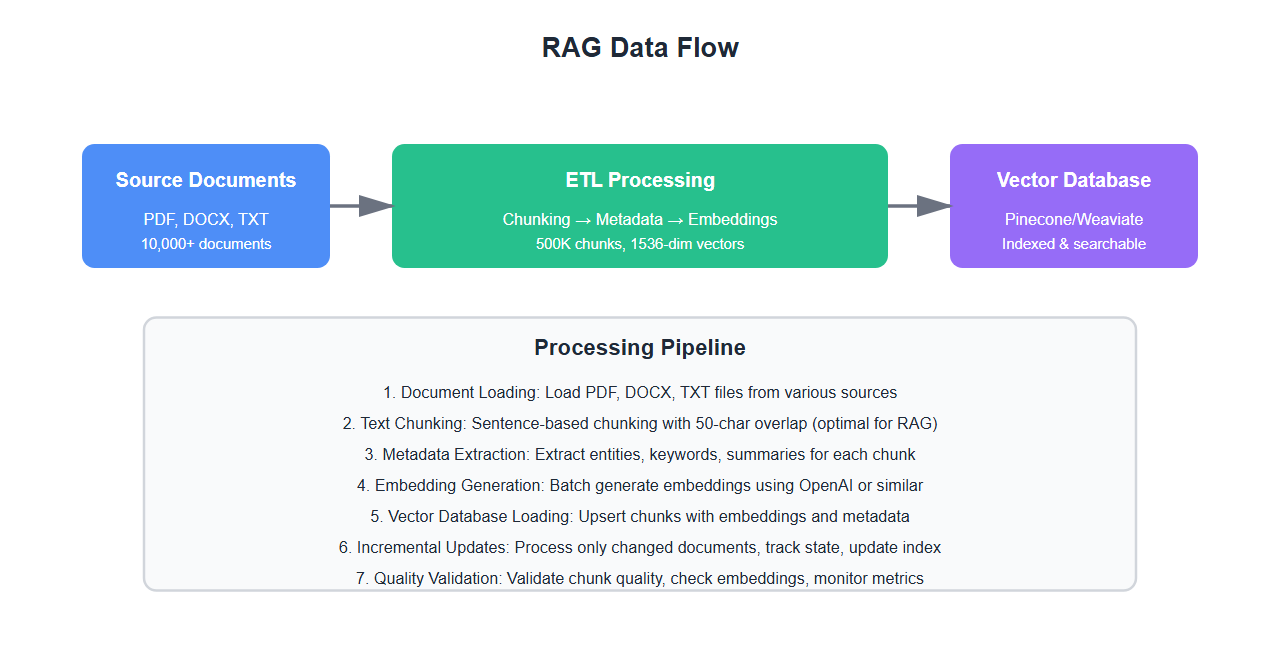
Complete ETL Pipeline
Build a complete pipeline:
from typing import List, Dict
from pathlib import Path
class RAGETLPipeline:
def __init__(self,
chunk_size: int = 500,
chunk_overlap: int = 50,
embedding_model: str = "text-embedding-3-small",
vector_db_api_key: str = None,
vector_db_index: str = None):
self.loader = DocumentLoader()
self.chunker = TextChunker(chunk_size=chunk_size, chunk_overlap=chunk_overlap)
self.metadata_extractor = MetadataExtractor()
self.embedding_gen = EmbeddingGenerator(model=embedding_model)
self.vector_loader = VectorDatabaseLoader(
api_key=vector_db_api_key,
index_name=vector_db_index
) if vector_db_api_key else None
def process_document(self, document_path: str) -> List[Dict]:
# Process single document
# Load
if document_path.endswith('.pdf'):
doc = self.loader.load_pdf(document_path)
elif document_path.endswith('.docx'):
doc = self.loader.load_docx(document_path)
else:
doc = self.loader.load_text(document_path)
# Chunk
chunks = self.chunker.chunk_by_sentences(doc["text"], doc["metadata"])
# Enrich metadata
enriched_chunks = []
for chunk in chunks:
enriched_metadata = self.metadata_extractor.enrich_metadata(
chunk, doc["metadata"]
)
enriched_chunks.append(Chunk(
text=chunk.text,
metadata=enriched_metadata,
chunk_id=chunk.chunk_id,
start_index=chunk.start_index,
end_index=chunk.end_index
))
# Generate embeddings
embedded_chunks = self.embedding_gen.generate_for_chunks(enriched_chunks)
# Load to vector database
if self.vector_loader:
self.vector_loader.upsert_chunks(embedded_chunks)
return embedded_chunks
def process_directory(self, directory: str) -> List[Dict]:
# Process all documents in directory
all_chunks = []
documents = self.loader.load_from_directory(directory)
for doc in documents:
chunks = self.chunker.chunk_by_sentences(doc["text"], doc["metadata"])
enriched_chunks = []
for chunk in chunks:
enriched_metadata = self.metadata_extractor.enrich_metadata(
chunk, doc["metadata"]
)
enriched_chunks.append(Chunk(
text=chunk.text,
metadata=enriched_metadata,
chunk_id=chunk.chunk_id,
start_index=chunk.start_index,
end_index=chunk.end_index
))
embedded_chunks = self.embedding_gen.generate_for_chunks(enriched_chunks)
all_chunks.extend(embedded_chunks)
# Batch load to vector database
if self.vector_loader:
self.vector_loader.upsert_chunks(all_chunks)
return all_chunks
# Usage
pipeline = RAGETLPipeline(
chunk_size=500,
chunk_overlap=50,
embedding_model="text-embedding-3-small",
vector_db_api_key="your-api-key",
vector_db_index="rag-index"
)
# Process single document
chunks = pipeline.process_document("document.pdf")
# Process directory
all_chunks = pipeline.process_directory("documents/")
Incremental Updates
Handle incremental document updates:
import hashlib
from datetime import datetime
class IncrementalRAGPipeline(RAGETLPipeline):
def __init__(self, state_file: str = "rag_state.json", *args, **kwargs):
super().__init__(*args, **kwargs)
self.state_file = state_file
self.processed_files = self._load_state()
def _load_state(self) -> Dict:
# Load processing state
try:
with open(self.state_file, 'r') as f:
return json.load(f)
except FileNotFoundError:
return {"processed_files": {}, "last_updated": None}
def _save_state(self):
# Save processing state
state = {
"processed_files": self.processed_files,
"last_updated": datetime.now().isoformat()
}
with open(self.state_file, 'w') as f:
json.dump(state, f, indent=2)
def _file_hash(self, file_path: str) -> str:
# Calculate file hash
with open(file_path, 'rb') as f:
return hashlib.md5(f.read()).hexdigest()
def process_incremental(self, document_path: str) -> List[Dict]:
# Process only if file changed
file_hash = self._file_hash(document_path)
state = self._load_state()
if document_path in state.get("processed_files", {}):
if state["processed_files"][document_path]["hash"] == file_hash:
# File unchanged, skip
return []
# Process document
chunks = self.process_document(document_path)
# Update state
state["processed_files"][document_path] = {
"hash": file_hash,
"processed_at": datetime.now().isoformat(),
"chunks": len(chunks)
}
self._save_state()
return chunks
# Usage
incremental_pipeline = IncrementalRAGPipeline(
state_file="rag_state.json",
vector_db_api_key="your-api-key",
vector_db_index="rag-index"
)
# Only processes changed files
chunks = incremental_pipeline.process_incremental("document.pdf")


Best Practices: Lessons from 50+ RAG Systems
From building RAG ETL pipelines:
- Optimal chunking: Use sentence or paragraph-based chunking. Character-based loses context.
- Overlap: Use 10-20% overlap between chunks. Preserves context across boundaries.
- Rich metadata: Extract entities, keywords, summaries. Improves retrieval quality.
- Batch processing: Process embeddings in batches. Reduces API calls and costs.
- Incremental updates: Process only changed documents. Saves time and resources.
- Error handling: Handle API failures gracefully. Retry with exponential backoff.
- Monitoring: Track processing metrics. Monitor embedding quality and costs.
- Testing: Test chunking strategies. Different content types need different approaches.
- Versioning: Version your embeddings. Track model and chunking changes.
- Cost optimization: Use appropriate embedding models. Balance quality and cost.
- Quality validation: Validate chunk quality. Check for empty or malformed chunks.
- Documentation: Document chunking strategies. Enables maintenance and debugging.

Common Mistakes and How to Avoid Them
What I learned the hard way:
- Poor chunking: Use sentence/paragraph-based chunking. Character-based loses context.
- No overlap: Use chunk overlap. Prevents context loss at boundaries.
- Missing metadata: Extract rich metadata. Improves retrieval quality significantly.
- No incremental processing: Process only changed documents. Full reprocessing is wasteful.
- Poor error handling: Handle API failures. Embedding APIs can fail or rate limit.
- No monitoring: Monitor processing metrics. Track costs and quality.
- Ignoring costs: Optimize embedding costs. Large datasets are expensive.
- No testing: Test chunking strategies. Different content needs different approaches.
- No versioning: Version your embeddings. Track changes over time.
- Poor quality validation: Validate chunk quality. Empty chunks hurt retrieval.
Real-World Example: Building RAG for 10,000 Documents
We built a RAG ETL pipeline for 10,000 documents:
- Chunking: Sentence-based chunking with 50-character overlap
- Metadata: Extracted entities, keywords, and summaries for each chunk
- Embeddings: Generated 500K embeddings using text-embedding-3-small
- Indexing: Loaded into Pinecone with proper metadata
- Incremental: Processed only changed documents daily
Key learnings: Sentence-based chunking with overlap works best, rich metadata significantly improves retrieval, and incremental processing is essential for large datasets.
🎯 Key Takeaway
RAG ETL requires specialized processing. Use optimal chunking strategies with overlap, extract rich metadata, generate embeddings efficiently, and handle incremental updates. With proper ETL, you ensure high-quality vector embeddings that produce better retrieval results.
Bottom Line
RAG ETL requires specialized data preparation. Use optimal chunking strategies with overlap, extract rich metadata, generate embeddings efficiently, and handle incremental updates. With proper ETL, you ensure high-quality vector embeddings that produce better retrieval results. The investment in proper ETL pays off in retrieval quality.
Discover more from C4: Container, Code, Cloud & Context
Subscribe to get the latest posts sent to your email.