Designing RESTful APIs for LLMs requires careful consideration. After building 30+ LLM APIs, I’ve learned what works. Here’s the complete guide to RESTful AI API design.
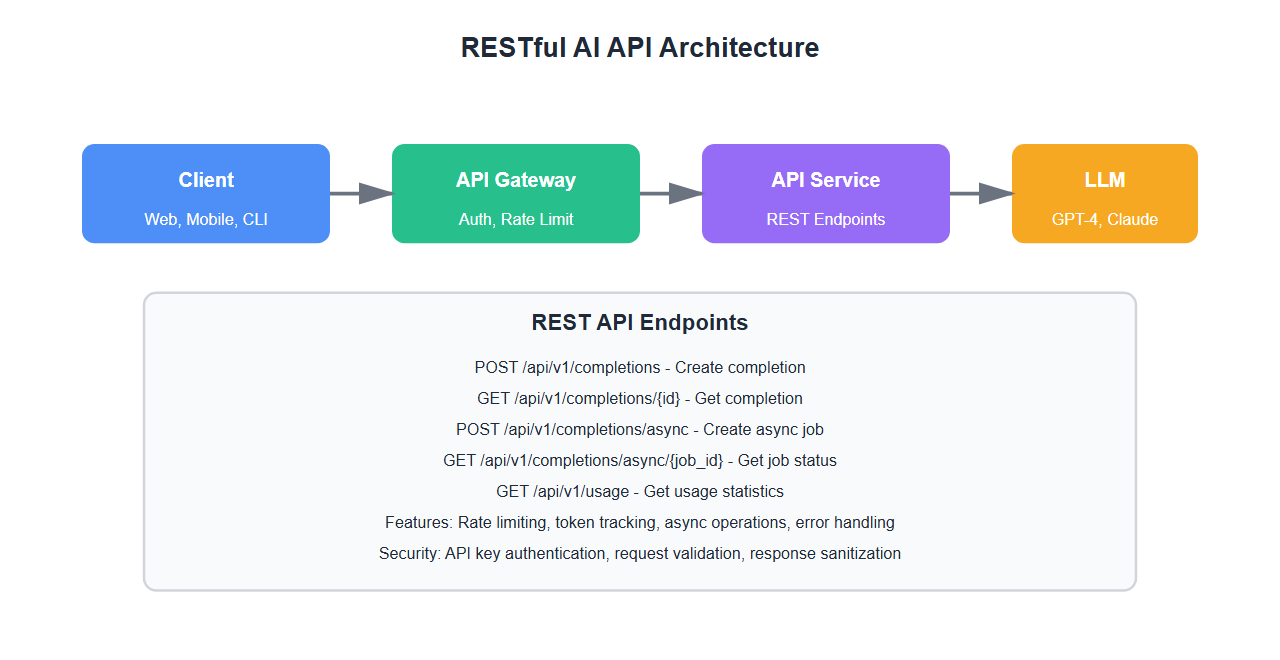
Why LLM APIs Are Different
LLM APIs have unique requirements:
- Async operations: LLM inference can take seconds or minutes
- Streaming responses: Need to stream tokens as they’re generated
- Rate limiting: LLM calls are expensive and need careful rate limiting
- Token management: Track token usage and costs
- Error handling: Handle timeouts, rate limits, and model errors gracefully
After building multiple LLM APIs, I’ve learned that proper API design is critical for production success.
API Design Principles
1. Resource-Based Design
Design APIs around resources, not actions:
from flask import Flask, request, jsonify
from typing import Dict, Optional
import uuid
from datetime import datetime
app = Flask(__name__)
# Good: Resource-based
# POST /api/v1/completions
# GET /api/v1/completions/{id}
# DELETE /api/v1/completions/{id}
# Bad: Action-based
# POST /api/v1/create_completion
# GET /api/v1/get_completion
# POST /api/v1/delete_completion
class CompletionResource:
def __init__(self):
self.completions = {}
def create(self, request_data: Dict) -> Dict:
# Create completion resource
completion_id = str(uuid.uuid4())
completion = {
"id": completion_id,
"prompt": request_data.get("prompt"),
"model": request_data.get("model", "gpt-4"),
"status": "processing",
"created_at": datetime.now().isoformat()
}
self.completions[completion_id] = completion
return completion
def get(self, completion_id: str) -> Optional[Dict]:
# Get completion resource
return self.completions.get(completion_id)
def delete(self, completion_id: str) -> bool:
# Delete completion resource
if completion_id in self.completions:
del self.completions[completion_id]
return True
return False
completion_resource = CompletionResource()
@app.route('/api/v1/completions', methods=['POST'])
def create_completion():
data = request.json
completion = completion_resource.create(data)
return jsonify(completion), 201
@app.route('/api/v1/completions/<completion_id>', methods=['GET'])
def get_completion(completion_id):
completion = completion_resource.get(completion_id)
if completion:
return jsonify(completion), 200
return jsonify({"error": "Not found"}), 404
@app.route('/api/v1/completions/<completion_id>', methods=['DELETE'])
def delete_completion(completion_id):
if completion_resource.delete(completion_id):
return jsonify({"status": "deleted"}), 200
return jsonify({"error": "Not found"}), 404
2. Proper HTTP Methods
Use HTTP methods correctly:
# GET: Retrieve resources
@app.route('/api/v1/completions/<completion_id>', methods=['GET'])
def get_completion(completion_id):
# Retrieve single resource
pass
# POST: Create resources
@app.route('/api/v1/completions', methods=['POST'])
def create_completion():
# Create new resource
pass
# PUT: Update entire resource
@app.route('/api/v1/completions/<completion_id>', methods=['PUT'])
def update_completion(completion_id):
# Replace entire resource
pass
# PATCH: Partial update
@app.route('/api/v1/completions/<completion_id>', methods=['PATCH'])
def patch_completion(completion_id):
# Update part of resource
pass
# DELETE: Delete resource
@app.route('/api/v1/completions/<completion_id>', methods=['DELETE'])
def delete_completion(completion_id):
# Delete resource
pass
3. Status Codes
Use appropriate HTTP status codes:
from flask import jsonify
# Success codes
def success_response(data: Dict, status_code: int = 200):
return jsonify(data), status_code
# 200 OK: Successful GET, PUT, PATCH, DELETE
@app.route('/api/v1/completions/<completion_id>', methods=['GET'])
def get_completion(completion_id):
completion = get_completion_by_id(completion_id)
if completion:
return success_response(completion, 200)
return error_response("Not found", 404)
# 201 Created: Successful POST
@app.route('/api/v1/completions', methods=['POST'])
def create_completion():
completion = create_new_completion(request.json)
return success_response(completion, 201)
# 202 Accepted: Async operation accepted
@app.route('/api/v1/completions', methods=['POST'])
def create_completion_async():
job_id = queue_completion_task(request.json)
return success_response({"job_id": job_id, "status": "accepted"}, 202)
# 204 No Content: Successful DELETE
@app.route('/api/v1/completions/<completion_id>', methods=['DELETE'])
def delete_completion(completion_id):
delete_completion_by_id(completion_id)
return "", 204
# Error codes
def error_response(message: str, status_code: int):
return jsonify({"error": message}), status_code
# 400 Bad Request: Invalid input
# 401 Unauthorized: Authentication required
# 403 Forbidden: Not authorized
# 404 Not Found: Resource doesn't exist
# 429 Too Many Requests: Rate limit exceeded
# 500 Internal Server Error: Server error
# 503 Service Unavailable: Service down
4. Request/Response Format
Design consistent request and response formats:
from typing import Dict, List, Optional
from dataclasses import dataclass, asdict
from datetime import datetime
@dataclass
class CompletionRequest:
prompt: str
model: str = "gpt-4"
max_tokens: int = 1000
temperature: float = 0.7
stream: bool = False
def validate(self) -> List[str]:
# Validate request
errors = []
if not self.prompt or len(self.prompt.strip()) == 0:
errors.append("prompt is required")
if self.max_tokens < 1 or self.max_tokens > 4000:
errors.append("max_tokens must be between 1 and 4000")
if self.temperature < 0 or self.temperature > 2:
errors.append("temperature must be between 0 and 2")
return errors
@dataclass
class CompletionResponse:
id: str
object: str = "completion"
created: int
model: str
choices: List[Dict]
usage: Dict
def to_dict(self) -> Dict:
return asdict(self)
@dataclass
class ErrorResponse:
error: Dict
def to_dict(self) -> Dict:
return asdict(self)
# Usage
@app.route('/api/v1/completions', methods=['POST'])
def create_completion():
try:
# Parse and validate request
request_data = request.json
completion_req = CompletionRequest(**request_data)
validation_errors = completion_req.validate()
if validation_errors:
error_response = ErrorResponse({
"type": "invalid_request",
"message": "Validation failed",
"errors": validation_errors
})
return jsonify(error_response.to_dict()), 400
# Process completion
result = process_completion(completion_req)
# Create response
response = CompletionResponse(
id=result["id"],
created=int(datetime.now().timestamp()),
model=completion_req.model,
choices=result["choices"],
usage=result["usage"]
)
return jsonify(response.to_dict()), 201
except Exception as e:
error_response = ErrorResponse({
"type": "server_error",
"message": str(e)
})
return jsonify(error_response.to_dict()), 500
5. Error Handling
Implement comprehensive error handling:
from flask import jsonify
from typing import Dict
class APIError(Exception):
def __init__(self, message: str, status_code: int = 400, error_type: str = "invalid_request"):
self.message = message
self.status_code = status_code
self.error_type = error_type
class ValidationError(APIError):
def __init__(self, message: str, errors: List[str] = None):
super().__init__(message, 400, "validation_error")
self.errors = errors or []
class RateLimitError(APIError):
def __init__(self, message: str = "Rate limit exceeded", retry_after: int = 60):
super().__init__(message, 429, "rate_limit_error")
self.retry_after = retry_after
class ModelError(APIError):
def __init__(self, message: str):
super().__init__(message, 502, "model_error")
@app.errorhandler(APIError)
def handle_api_error(error: APIError):
response = {
"error": {
"type": error.error_type,
"message": error.message
}
}
if isinstance(error, ValidationError) and error.errors:
response["error"]["errors"] = error.errors
if isinstance(error, RateLimitError):
response["error"]["retry_after"] = error.retry_after
return jsonify(response), error.status_code
@app.errorhandler(404)
def handle_not_found(error):
return jsonify({
"error": {
"type": "not_found",
"message": "Resource not found"
}
}), 404
@app.errorhandler(500)
def handle_internal_error(error):
return jsonify({
"error": {
"type": "internal_error",
"message": "Internal server error"
}
}), 500
# Usage
@app.route('/api/v1/completions', methods=['POST'])
def create_completion():
# Validate
if not request.json or "prompt" not in request.json:
raise ValidationError("prompt is required", ["prompt"])
# Check rate limit
if is_rate_limited(request.remote_addr):
raise RateLimitError(retry_after=60)
# Process
try:
result = call_llm(request.json)
return jsonify(result), 201
except TimeoutError:
raise ModelError("Model request timed out")
except Exception as e:
raise APIError(f"Processing failed: {str(e)}", 500)
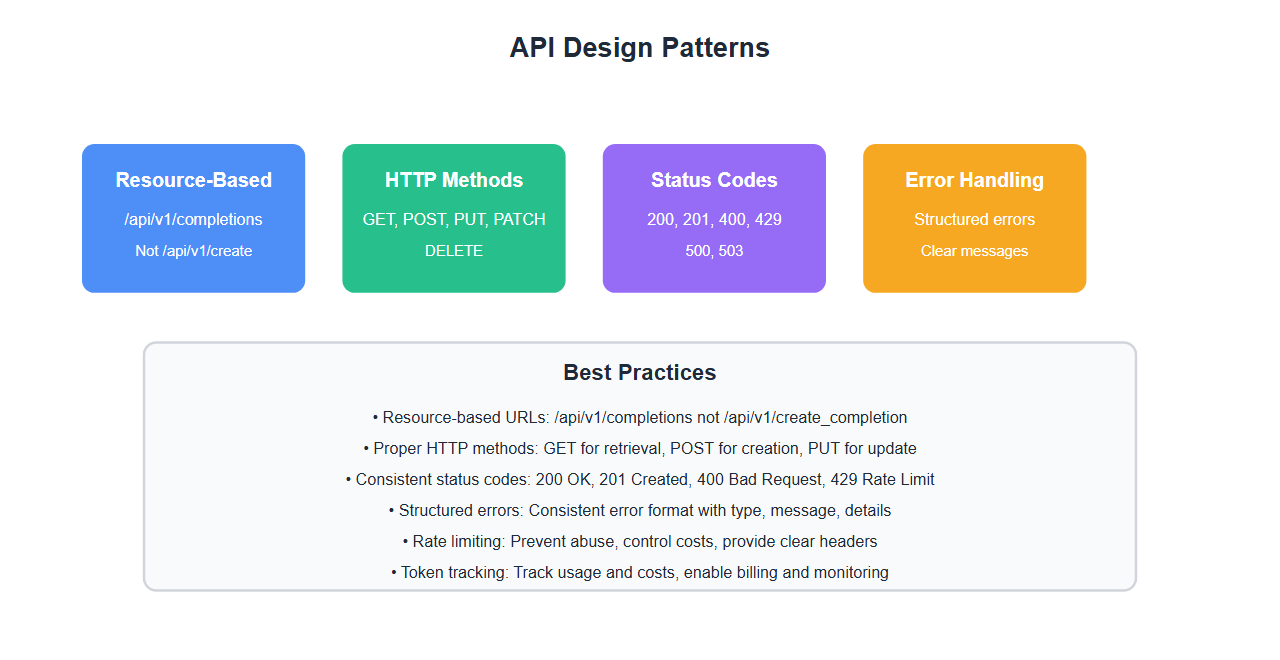
Advanced Patterns
1. Async Operations
Handle long-running LLM operations asynchronously:
from flask import Flask, jsonify
import uuid
from datetime import datetime
from enum import Enum
class JobStatus(Enum):
PENDING = "pending"
PROCESSING = "processing"
COMPLETED = "completed"
FAILED = "failed"
class AsyncCompletionService:
def __init__(self):
self.jobs = {}
def create_job(self, request_data: Dict) -> Dict:
# Create async job
job_id = str(uuid.uuid4())
job = {
"id": job_id,
"status": JobStatus.PENDING.value,
"request": request_data,
"created_at": datetime.now().isoformat(),
"result": None,
"error": None
}
self.jobs[job_id] = job
# Queue for processing
queue_job(job_id)
return job
def get_job_status(self, job_id: str) -> Optional[Dict]:
# Get job status
return self.jobs.get(job_id)
def get_job_result(self, job_id: str) -> Optional[Dict]:
# Get job result if completed
job = self.jobs.get(job_id)
if job and job["status"] == JobStatus.COMPLETED.value:
return job["result"]
return None
async_service = AsyncCompletionService()
@app.route('/api/v1/completions/async', methods=['POST'])
def create_async_completion():
job = async_service.create_job(request.json)
return jsonify(job), 202 # Accepted
@app.route('/api/v1/completions/async/<job_id>', methods=['GET'])
def get_job_status(job_id):
job = async_service.get_job_status(job_id)
if job:
return jsonify(job), 200
return jsonify({"error": "Job not found"}), 404
@app.route('/api/v1/completions/async/<job_id>/result', methods=['GET'])
def get_job_result(job_id):
result = async_service.get_job_result(job_id)
if result:
return jsonify(result), 200
return jsonify({"error": "Result not available"}), 404
2. Rate Limiting
Implement rate limiting for LLM APIs:
from functools import wraps
from datetime import datetime, timedelta
from collections import defaultdict
import time
class RateLimiter:
def __init__(self, max_requests: int = 100, window_seconds: int = 60):
self.max_requests = max_requests
self.window_seconds = window_seconds
self.requests = defaultdict(list)
def is_allowed(self, identifier: str) -> tuple:
# Check if request is allowed
now = time.time()
window_start = now - self.window_seconds
# Clean old requests
self.requests[identifier] = [
req_time for req_time in self.requests[identifier]
if req_time > window_start
]
# Check limit
if len(self.requests[identifier]) >= self.max_requests:
retry_after = int(self.window_seconds - (now - self.requests[identifier][0]))
return False, retry_after
# Record request
self.requests[identifier].append(now)
return True, 0
def get_remaining(self, identifier: str) -> int:
# Get remaining requests
now = time.time()
window_start = now - self.window_seconds
self.requests[identifier] = [
req_time for req_time in self.requests[identifier]
if req_time > window_start
]
return max(0, self.max_requests - len(self.requests[identifier]))
rate_limiter = RateLimiter(max_requests=100, window_seconds=60)
def rate_limit(f):
@wraps(f)
def decorated_function(*args, **kwargs):
# Get identifier (IP, API key, user ID, etc.)
identifier = request.headers.get('X-API-Key') or request.remote_addr
allowed, retry_after = rate_limiter.is_allowed(identifier)
if not allowed:
response = jsonify({
"error": {
"type": "rate_limit_error",
"message": "Rate limit exceeded",
"retry_after": retry_after
}
})
response.headers['Retry-After'] = str(retry_after)
return response, 429
# Add rate limit headers
remaining = rate_limiter.get_remaining(identifier)
response = f(*args, **kwargs)
response.headers['X-RateLimit-Limit'] = str(rate_limiter.max_requests)
response.headers['X-RateLimit-Remaining'] = str(remaining)
response.headers['X-RateLimit-Reset'] = str(int(time.time()) + rate_limiter.window_seconds)
return response
return decorated_function
@app.route('/api/v1/completions', methods=['POST'])
@rate_limit
def create_completion():
# Rate-limited endpoint
return jsonify({"status": "ok"}), 201
3. Token Usage Tracking
Track token usage and costs:
from typing import Dict
from dataclasses import dataclass
@dataclass
class TokenUsage:
prompt_tokens: int
completion_tokens: int
total_tokens: int
@property
def cost(self) -> float:
# Calculate cost based on model pricing
# This is simplified - actual pricing varies by model
prompt_cost = self.prompt_tokens * 0.00003 # $0.03 per 1K tokens
completion_cost = self.completion_tokens * 0.00006 # $0.06 per 1K tokens
return prompt_cost + completion_cost
class TokenTracker:
def __init__(self):
self.usage_by_api_key = defaultdict(lambda: {
"total_tokens": 0,
"total_cost": 0.0,
"requests": 0
})
def record_usage(self, api_key: str, usage: TokenUsage):
# Record token usage
stats = self.usage_by_api_key[api_key]
stats["total_tokens"] += usage.total_tokens
stats["total_cost"] += usage.cost
stats["requests"] += 1
def get_usage(self, api_key: str) -> Dict:
# Get usage statistics
return self.usage_by_api_key.get(api_key, {
"total_tokens": 0,
"total_cost": 0.0,
"requests": 0
})
token_tracker = TokenTracker()
@app.route('/api/v1/completions', methods=['POST'])
def create_completion():
# Process completion
result = process_completion(request.json)
# Track usage
usage = TokenUsage(
prompt_tokens=result["usage"]["prompt_tokens"],
completion_tokens=result["usage"]["completion_tokens"],
total_tokens=result["usage"]["total_tokens"]
)
api_key = request.headers.get('X-API-Key')
if api_key:
token_tracker.record_usage(api_key, usage)
# Include usage in response
result["usage"]["cost"] = usage.cost
return jsonify(result), 201
@app.route('/api/v1/usage', methods=['GET'])
def get_usage():
api_key = request.headers.get('X-API-Key')
if not api_key:
return jsonify({"error": "API key required"}), 401
usage = token_tracker.get_usage(api_key)
return jsonify(usage), 200


Best Practices: Lessons from 30+ LLM APIs
From building production LLM APIs:
- Resource-based design: Design around resources, not actions. Makes APIs intuitive and RESTful.
- Proper HTTP methods: Use GET, POST, PUT, PATCH, DELETE correctly. Follow REST conventions.
- Consistent status codes: Use appropriate HTTP status codes. Helps clients handle responses correctly.
- Error handling: Implement comprehensive error handling. Provide clear error messages.
- Rate limiting: Implement rate limiting. Prevents abuse and controls costs.
- Token tracking: Track token usage and costs. Enables cost management and billing.
- Async operations: Support async operations for long-running tasks. Improves user experience.
- Versioning: Version your APIs. Enables evolution without breaking clients.
- Documentation: Document APIs thoroughly. Use OpenAPI/Swagger specifications.
- Monitoring: Monitor API performance and errors. Track latency, errors, and usage.
- Security: Implement authentication and authorization. Protect sensitive operations.
- Testing: Test APIs thoroughly. Include unit, integration, and load tests.

Common Mistakes and How to Avoid Them
What I learned the hard way:
- Action-based URLs: Use resource-based URLs. Action-based URLs aren’t RESTful.
- Wrong HTTP methods: Use correct HTTP methods. GET for retrieval, POST for creation.
- Poor error handling: Implement proper error handling. Generic errors don’t help clients.
- No rate limiting: Implement rate limiting. Prevents abuse and controls costs.
- Ignoring async: Support async operations. Long-running tasks need async patterns.
- No token tracking: Track token usage. Essential for cost management.
- No versioning: Version your APIs. Breaking changes hurt clients.
- Poor documentation: Document thoroughly. Undocumented APIs are unusable.
- No monitoring: Monitor API performance. Can’t improve what you don’t measure.
- Weak security: Implement proper security. APIs are attack vectors.
Real-World Example: Production LLM API
We built a production LLM API handling 1M+ requests/month:
- Design: Resource-based REST API with proper HTTP methods
- Async: Async operations for long-running completions
- Rate limiting: Tiered rate limiting (100/min for free, 1000/min for paid)
- Token tracking: Real-time token usage and cost tracking
- Monitoring: Comprehensive monitoring with alerts
Key learnings: Proper API design reduces support burden, rate limiting prevents abuse, and token tracking enables cost management.
🎯 Key Takeaway
RESTful AI API design requires careful consideration of LLM-specific requirements. Use resource-based design, proper HTTP methods, comprehensive error handling, rate limiting, and token tracking. With proper API design, you create APIs that are intuitive, reliable, and cost-effective.
Bottom Line
RESTful AI API design requires understanding both REST principles and LLM-specific requirements. Use resource-based design, proper HTTP methods, comprehensive error handling, rate limiting, and token tracking. With proper API design, you create APIs that are intuitive, reliable, and cost-effective. The investment in proper API design pays off in developer experience and operational efficiency.
Discover more from C4: Container, Code, Cloud & Context
Subscribe to get the latest posts sent to your email.