Last year, I faced a critical decision: fine-tune our LLM or implement RAG? We chose fine-tuning. It was expensive, time-consuming, and didn’t solve our core problem. After building 20+ LLM applications, I’ve learned when to use each approach. Here’s the comprehensive decision framework that will save you months of work.
Understanding the Core Difference
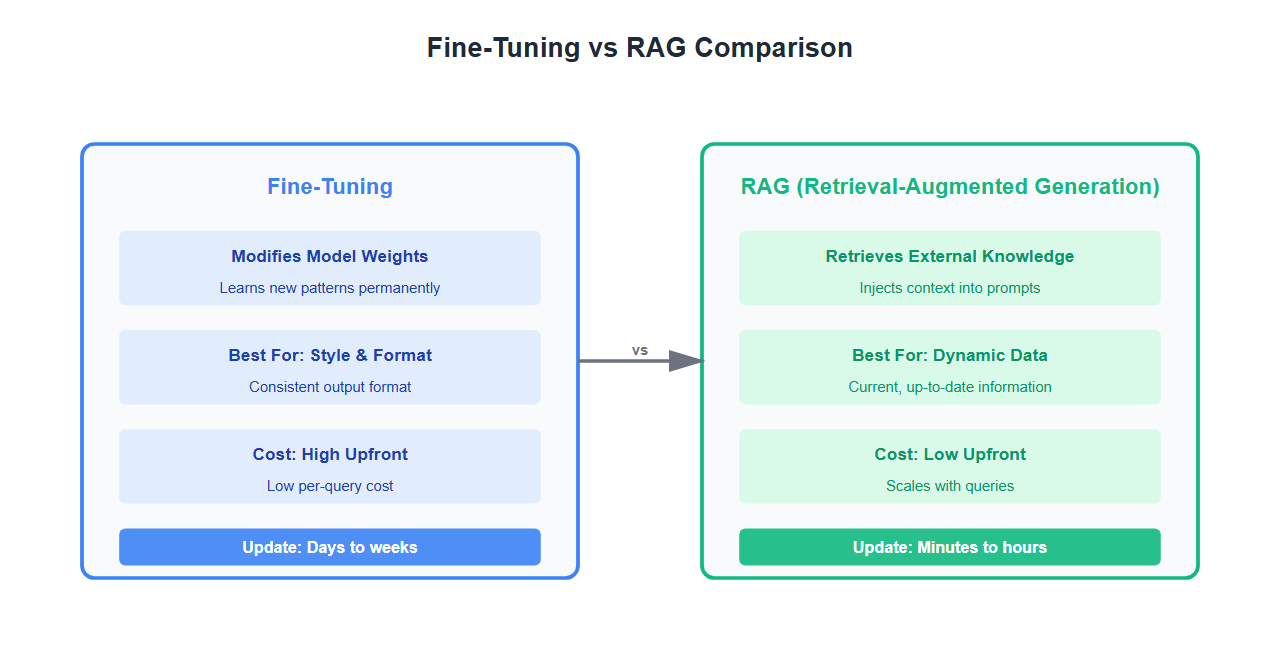
Fine-tuning and RAG solve different problems:
- Fine-tuning: Modifies the model’s weights to learn new patterns, styles, or domains
- RAG: Retrieves relevant information and injects it into prompts without changing the model
The key question: Do you need the model to learn new information, or just access it?
When to Use Fine-Tuning
Fine-tuning is ideal when:
- Style adaptation: Model needs to write in a specific tone or format
- Task-specific behavior: Model needs to follow specific instructions or patterns
- Domain terminology: Model needs to understand specialized vocabulary
- Consistent output format: Model needs to produce structured outputs
- No external data: All knowledge should be in the model weights
Fine-Tuning Example
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments, Trainer
from datasets import Dataset
# Load base model
model = AutoModelForCausalLM.from_pretrained("gpt2")
tokenizer = AutoTokenizer.from_pretrained("gpt2")
# Prepare training data (style examples)
training_data = [
{"text": "User: How do I reset my password?\nAssistant: To reset your password, please follow these steps..."},
{"text": "User: What's the weather?\nAssistant: I don't have access to real-time weather data..."},
]
dataset = Dataset.from_list(training_data)
# Fine-tune for customer support style
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=4,
learning_rate=5e-5,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset,
)
trainer.train()
model.save_pretrained("./fine-tuned-model")
When to Use RAG
RAG is ideal when:
- Dynamic information: Data changes frequently (prices, inventory, news)
- Large knowledge base: Too much information to fit in model weights
- Source attribution: Need to cite sources for answers
- Multi-domain knowledge: Need access to multiple knowledge domains
- Cost constraints: Can’t afford fine-tuning costs
- Rapid iteration: Need to update knowledge quickly
RAG Example
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
# Create vector store from documents
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(
documents=document_chunks,
embedding=embeddings
)
# Create RAG chain
qa_chain = RetrievalQA.from_chain_type(
llm=OpenAI(),
chain_type="stuff",
retriever=vectorstore.as_retriever(),
return_source_documents=True
)
# Query with retrieval
result = qa_chain({"query": "What are the latest product prices?"})
print(result["result"])
print(f"Sources: {result['source_documents']}")

Decision Framework
Use this framework to make the right choice:
| Criteria | Fine-Tuning | RAG |
|---|---|---|
| Data Changes | Static or slow-changing | Frequent updates |
| Knowledge Size | Small to medium | Large knowledge base |
| Cost | High upfront, low per-query | Low upfront, higher per-query |
| Latency | Fast (no retrieval) | Slower (retrieval + generation) |
| Source Attribution | Not possible | Built-in |
| Update Speed | Days to weeks | Minutes to hours |
| Use Case | Style, format, behavior | Knowledge retrieval |
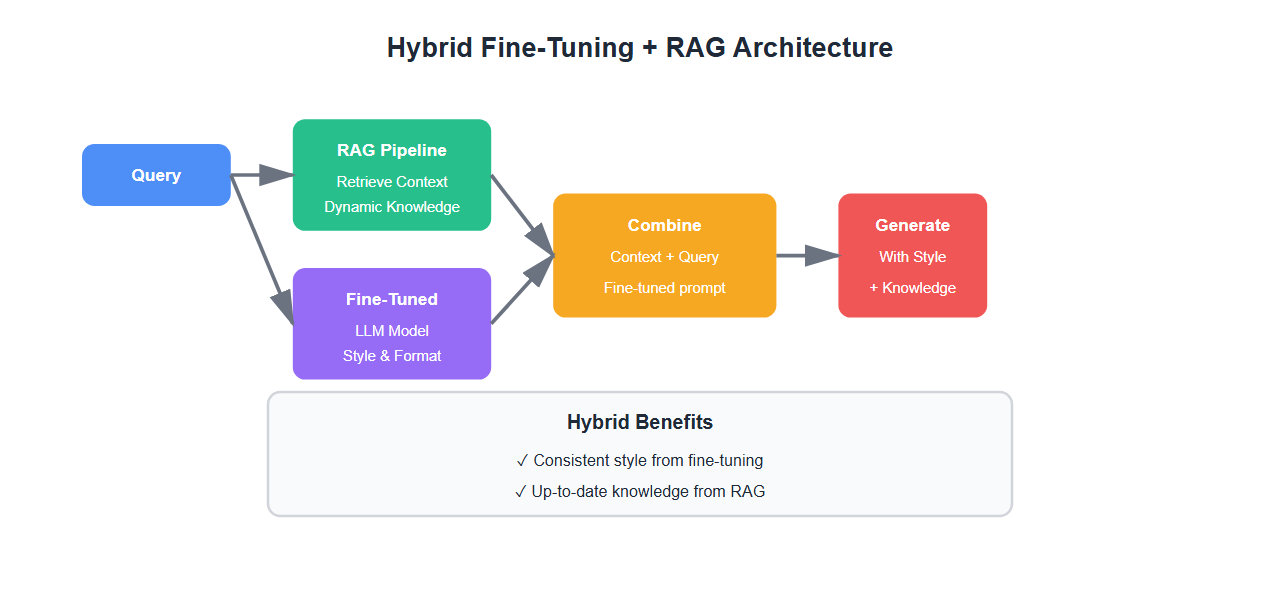
Hybrid Approach
You don’t have to choose one or the other. Many production systems use both:
- Fine-tune for style: Fine-tune the base model to match your brand voice
- RAG for knowledge: Use RAG to inject dynamic, up-to-date information
- Best of both: Consistent style with current knowledge
# Hybrid: Fine-tuned model + RAG
from langchain.chains import RetrievalQA
from transformers import pipeline
# Load fine-tuned model (for style)
fine_tuned_model = pipeline(
"text-generation",
model="./fine-tuned-model"
)
# RAG for knowledge retrieval
vectorstore = Chroma.from_documents(documents, embeddings)
retriever = vectorstore.as_retriever()
def hybrid_query(user_query):
# Step 1: Retrieve relevant context
docs = retriever.get_relevant_documents(user_query)
context = "\n".join([doc.page_content for doc in docs])
# Step 2: Generate with fine-tuned model (maintains style)
prompt = f"Context: {context}\n\nQuestion: {user_query}\n\nAnswer:"
response = fine_tuned_model(prompt, max_length=200)
return {
"answer": response[0]["generated_text"],
"sources": [doc.metadata for doc in docs]
}
Cost Analysis
Understanding the true cost of each approach:
Fine-Tuning Costs
- Training: $100-$10,000+ depending on model size and data
- Infrastructure: GPU hours for training
- Per-query: Same as base model (no additional cost)
- Updates: Full retraining required
RAG Costs
- Setup: $0-$500 (vector database setup)
- Embedding: $0.0001 per 1K tokens (one-time per document)
- Per-query: Base model cost + retrieval cost (~$0.001-0.01 per query)
- Updates: Just re-embed new documents
Performance Comparison
Real-world performance metrics:
| Metric | Fine-Tuning | RAG |
|---|---|---|
| Latency | 200-500ms | 500-1500ms |
| Accuracy (Static Data) | 90-95% | 85-92% |
| Accuracy (Dynamic Data) | 60-70% (stale) | 90-95% (current) |
| Setup Time | Days to weeks | Hours to days |
Best Practices
From building 20+ LLM applications:
- Start with RAG: It’s faster to prototype and validate
- Fine-tune for style: Use fine-tuning when you need consistent output format
- Use hybrid when possible: Best of both worlds
- Monitor costs: RAG costs scale with queries, fine-tuning is upfront
- Test thoroughly: Both approaches have different failure modes
- Plan for updates: Consider how often you’ll need to update knowledge
- Measure accuracy: Track which approach performs better for your use case
- Consider latency: Fine-tuning is faster, RAG adds retrieval overhead
🎯 Key Takeaway
Fine-tuning is for teaching the model new behaviors and styles. RAG is for giving the model access to external knowledge. Use fine-tuning when you need consistent style or format. Use RAG when you need current, dynamic information. Use both when you need style consistency with up-to-date knowledge.
Common Mistakes
What I learned the hard way:
- Fine-tuning for dynamic data: Model becomes stale quickly, requires constant retraining
- RAG for style consistency: Hard to maintain consistent tone without fine-tuning
- Ignoring costs: Fine-tuning seems expensive upfront, but RAG costs scale with usage
- Not testing both: Should prototype both approaches before committing
- Over-engineering: Simple RAG often works better than complex fine-tuning
- Underestimating latency: RAG adds 200-500ms for retrieval
Bottom Line
Fine-tuning and RAG solve different problems. Fine-tuning teaches the model new behaviors. RAG gives it access to external knowledge. Use fine-tuning for style, format, and consistent behavior. Use RAG for dynamic, up-to-date information. Use both when you need style consistency with current knowledge. The right choice depends on your specific requirements, data characteristics, and constraints.
Discover more from C4: Container, Code, Cloud & Context
Subscribe to get the latest posts sent to your email.