Three weeks after launching our AI customer support system, we noticed something strange. Response quality was degrading—slowly, almost imperceptibly. Users weren’t complaining yet, but satisfaction scores were dropping. The problem? We had no way to measure prompt performance. We were optimizing blind. That’s when I built a comprehensive prompt performance monitoring system.

Why Prompt Performance Matters
Prompt performance isn’t just about speed—it’s about quality, consistency, and user experience. A poorly performing prompt can:
- Generate irrelevant or incorrect responses
- Waste tokens and increase costs
- Frustrate users with slow responses
- Cause hallucinations or unsafe outputs
- Degrade over time without detection
Without monitoring, you’re flying blind. You won’t know when prompts degrade, which versions perform best, or how to optimize.
Key Metrics to Track
Effective prompt performance monitoring requires tracking multiple dimensions:
1. Response Quality Metrics
Measure how good the responses are:
- Relevance Score: How relevant is the response to the query?
- Accuracy Score: Is the information correct?
- Completeness: Does it answer the full question?
- Coherence: Is the response well-structured and logical?
- Safety Score: Does it avoid harmful or biased content?
class PromptQualityMonitor:
def __init__(self):
self.evaluator = load_evaluator()
def evaluate_response(self, query, response, context=None):
scores = {}
# Relevance
scores['relevance'] = self.evaluator.relevance(query, response)
# Accuracy (if context provided)
if context:
scores['accuracy'] = self.evaluator.accuracy(response, context)
# Completeness
scores['completeness'] = self.evaluator.completeness(query, response)
# Coherence
scores['coherence'] = self.evaluator.coherence(response)
# Safety
scores['safety'] = self.evaluator.safety(response)
return scores
def track_quality(self, prompt_version, query, response, scores):
# Store metrics
metrics = {
'prompt_version': prompt_version,
'timestamp': datetime.utcnow().isoformat(),
'scores': scores,
'overall_score': sum(scores.values()) / len(scores)
}
# Alert if quality drops
if metrics['overall_score'] < 0.7:
self.alert_quality_degradation(prompt_version, metrics)
return metrics

2. Performance Metrics
Track how efficiently prompts perform:
- Latency: Time to generate response
- Token Usage: Input and output tokens
- Cost per Request: Total cost including retries
- Success Rate: Percentage of successful completions
- Error Rate: Failed requests or timeouts
class PromptPerformanceTracker:
def track_request(self, prompt_version, start_time, tokens_in, tokens_out, cost, success):
latency = (datetime.utcnow() - start_time).total_seconds()
metrics = {
'prompt_version': prompt_version,
'latency_ms': latency * 1000,
'tokens_in': tokens_in,
'tokens_out': tokens_out,
'cost': cost,
'success': success,
'timestamp': datetime.utcnow().isoformat()
}
# Update aggregations
self.update_aggregations(prompt_version, metrics)
return metrics
def update_aggregations(self, version, metrics):
# Track P50, P95, P99 latencies
self.latency_histogram.observe(metrics['latency_ms'])
# Track token usage
self.token_counter.labels(version=version, type='input').inc(metrics['tokens_in'])
self.token_counter.labels(version=version, type='output').inc(metrics['tokens_out'])
# Track costs
self.cost_counter.labels(version=version).inc(metrics['cost'])
# Track success rate
if metrics['success']:
self.success_counter.labels(version=version).inc()
else:
self.error_counter.labels(version=version).inc()
3. Version Comparison
Compare different prompt versions to find the best performing one:
class PromptVersionComparator:
def compare_versions(self, version_a, version_b, time_window='7d'):
metrics_a = self.get_metrics(version_a, time_window)
metrics_b = self.get_metrics(version_b, time_window)
comparison = {
'quality': {
'a': metrics_a['avg_quality_score'],
'b': metrics_b['avg_quality_score'],
'winner': 'a' if metrics_a['avg_quality_score'] > metrics_b['avg_quality_score'] else 'b'
},
'latency': {
'a': metrics_a['p95_latency'],
'b': metrics_b['p95_latency'],
'winner': 'a' if metrics_a['p95_latency'] < metrics_b['p95_latency'] else 'b'
},
'cost': {
'a': metrics_a['avg_cost'],
'b': metrics_b['avg_cost'],
'winner': 'a' if metrics_a['avg_cost'] < metrics_b['avg_cost'] else 'b'
},
'success_rate': {
'a': metrics_a['success_rate'],
'b': metrics_b['success_rate'],
'winner': 'a' if metrics_a['success_rate'] > metrics_b['success_rate'] else 'b'
}
}
return comparison
Implementing Quality Evaluation
Quality evaluation can be done through multiple methods:
1. LLM-as-Judge
Use a more powerful LLM to evaluate responses:
def evaluate_with_llm_judge(query, response, context=None):
judge_prompt = "Evaluate this response for quality:\n\n"
judge_prompt += f"Query: {query}\n"
judge_prompt += f"Response: {response}\n"
if context:
judge_prompt += f"Context: {context}\n"
judge_prompt += "\nRate each dimension from 1-10:\n"
judge_prompt += "1. Relevance: How relevant is the response?\n"
judge_prompt += "2. Accuracy: Is the information correct?\n"
judge_prompt += "3. Completeness: Does it fully answer the question?\n"
judge_prompt += "4. Coherence: Is it well-structured?\n"
judge_prompt += "5. Safety: Is it safe and appropriate?\n\n"
judge_prompt += "Format: relevance=X, accuracy=Y, completeness=Z, coherence=W, safety=V"
evaluation = llm_judge.complete(judge_prompt)
# Parse scores
scores = parse_scores(evaluation)
return scores
2. Embedding-Based Similarity
Use embeddings to measure semantic similarity:
from sentence_transformers import SentenceTransformer
similarity_model = SentenceTransformer('all-MiniLM-L6-v2')
def evaluate_relevance(query, response):
query_embedding = similarity_model.encode(query)
response_embedding = similarity_model.encode(response)
similarity = cosine_similarity([query_embedding], [response_embedding])[0][0]
return similarity
3. Rule-Based Checks
Implement specific rules for your domain:
def evaluate_with_rules(response, query_type):
rules = {
'customer_support': [
check_contains_apology_if_negative,
check_provides_actionable_steps,
check_mentions_escalation_if_complex
],
'technical_documentation': [
check_includes_code_examples,
check_has_clear_structure,
check_mentions_related_topics
]
}
scores = {}
for rule in rules.get(query_type, []):
rule_name = rule.__name__
scores[rule_name] = rule(response)
return scores
Real-World Monitoring Dashboard
Our monitoring dashboard tracks:
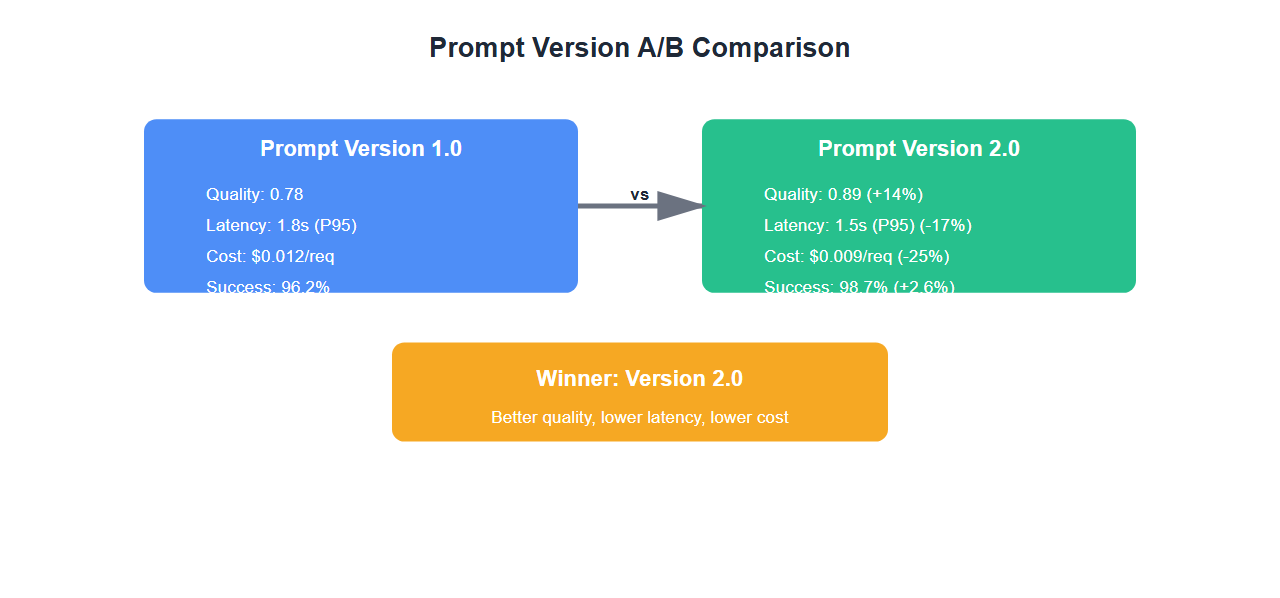
| Metric | Prompt v1.0 | Prompt v2.0 | Change |
|---|---|---|---|
| Avg Quality Score | 0.78 | 0.89 | +14% |
| P95 Latency | 1.8s | 1.5s | -17% |
| Avg Cost/Request | $0.012 | $0.009 | -25% |
| Success Rate | 96.2% | 98.7% | +2.6% |
| User Satisfaction | 4.1/5 | 4.6/5 | +12% |
Alerting Strategy
Set up alerts for critical issues:
- Quality Degradation: Alert if quality score drops below threshold
- Latency Spikes: Alert if P95 latency exceeds SLA
- Cost Anomalies: Alert if cost per request increases significantly
- Error Rate: Alert if success rate drops below threshold
- Version Regression: Alert if new version performs worse than previous
class PromptAlerting:
def check_alerts(self, prompt_version, metrics):
alerts = []
# Quality alert
if metrics['avg_quality'] < 0.7:
alerts.append({
'type': 'quality_degradation',
'severity': 'high',
'message': f"Quality score dropped to {metrics['avg_quality']:.2f}"
})
# Latency alert
if metrics['p95_latency'] > 3000: # 3 seconds
alerts.append({
'type': 'latency_spike',
'severity': 'medium',
'message': f"P95 latency is {metrics['p95_latency']:.0f}ms"
})
# Cost alert
if metrics['avg_cost'] > 0.02: # $0.02 per request
alerts.append({
'type': 'cost_anomaly',
'severity': 'medium',
'message': f"Average cost is ${metrics['avg_cost']:.3f}"
})
# Send alerts
for alert in alerts:
self.send_alert(alert)
return alerts
Best Practices
From our experience monitoring prompts in production:
- Version Everything: Tag every prompt with a version number
- Track Baselines: Establish baseline metrics before deploying changes
- Monitor Continuously: Don't just check after deployments—monitor always
- Compare Versions: Always A/B test new prompt versions
- Set Clear Thresholds: Define what "good" means for your use case
- Automate Alerts: Don't rely on manual checks
- Review Regularly: Weekly reviews of prompt performance trends
🎯 Key Takeaway
Prompt performance monitoring isn't optional—it's essential. Without it, you're optimizing blind. Track quality, performance, and cost metrics. Compare versions. Set up alerts. Your prompts will degrade over time if you don't monitor them.
Bottom Line
Prompt performance monitoring transformed our AI system from a black box into a data-driven, continuously improving system. We caught quality degradation early, optimized costs, and improved user satisfaction. Invest in monitoring from day one—you'll thank yourself later.
Discover more from C4: Container, Code, Cloud & Context
Subscribe to get the latest posts sent to your email.