The moment I first deployed a production generative AI application on AWS, I realised we had crossed a threshold that would fundamentally change how enterprises build intelligent systems. After spending two decades architecting solutions across every major cloud platform, I can say with confidence that AWS has assembled the most comprehensive generative AI ecosystem available today. This is not about marketing claims or feature comparisons — it is about what actually works when you need to ship production-grade AI applications at scale, with the governance, security, and cost controls that regulated industries demand.
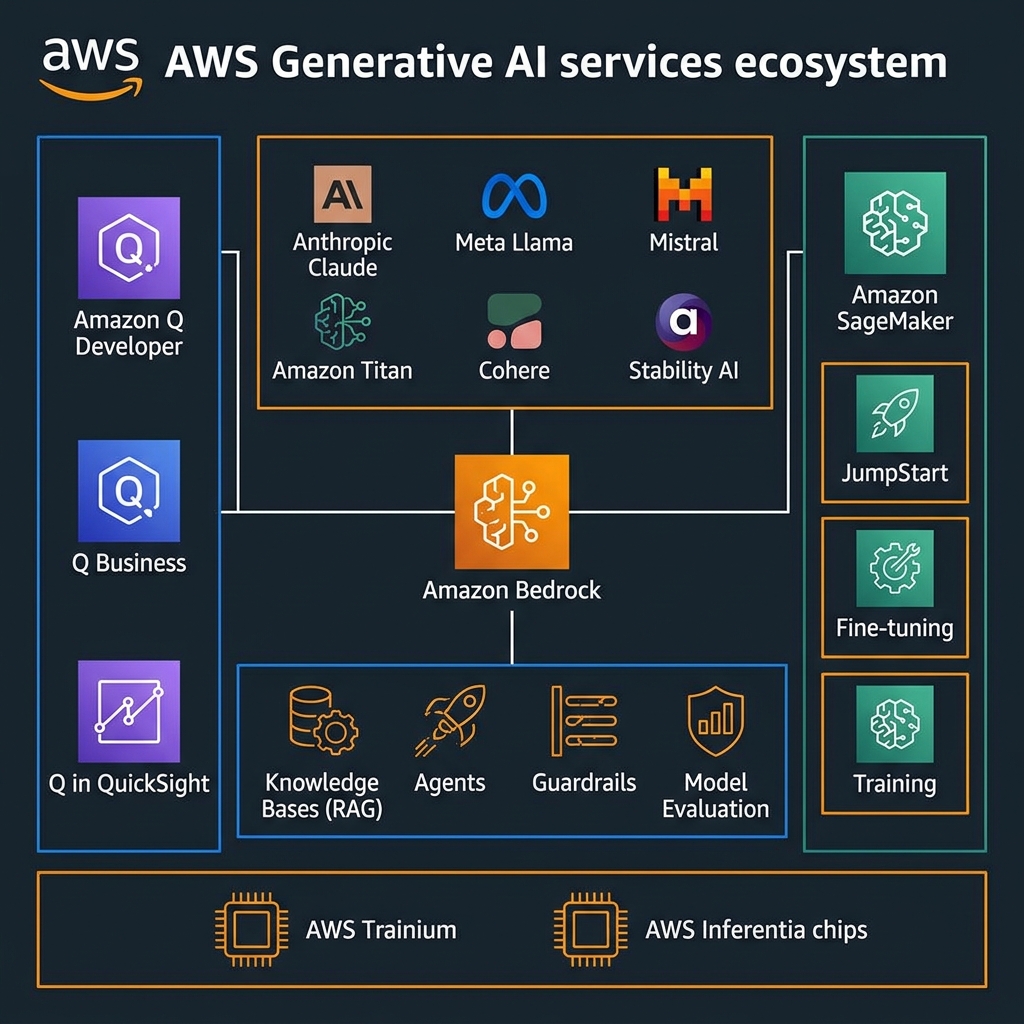
This article is a practitioner’s guide to the full AWS generative AI stack as of 2025 and into 2026. We cover the foundation model landscape, Bedrock’s enterprise features, Amazon Q in its business and developer variants, SageMaker’s role in custom model development, the custom silicon story, production architecture patterns, and the operational disciplines that separate successful deployments from expensive experiments.
The Foundation Model Landscape on AWS Bedrock
Amazon Bedrock is the gravitational centre of the AWS generative AI strategy, and for good reason. It provides a single, consistent API surface for accessing foundation models from Anthropic, Meta, Mistral, Cohere, AI21 Labs, Stability AI, and Amazon’s own Titan and Nova families. What makes this architecturally compelling is portability without rewriting. You call the same InvokeModel API regardless of which foundation model is serving the request, which means you can run model selection experiments, fall back to alternative models during service disruptions, or migrate to newer models as they become available, without touching application business logic.
The model catalogue has matured considerably. Anthropic’s Claude 3.5 Sonnet and Claude 3.5 Haiku represent the current sweet spot for enterprise applications: Sonnet for complex reasoning, multi-step planning, and document analysis that benefits from deep contextual understanding; Haiku for high-volume, latency-sensitive tasks where cost-per-token matters. Meta’s Llama 3.1 and 3.2 families offer genuinely competitive performance for open-weight workloads — particularly valuable when organizations need to run inference in isolated environments or want to fine-tune on proprietary data without sending it to third-party model providers. Amazon’s Nova models (Micro, Lite, Pro) represent the best price-performance ratio for AWS-native workloads where enterprise support SLAs are non-negotiable.
Bedrock Knowledge Bases: Managed RAG Without the Plumbing
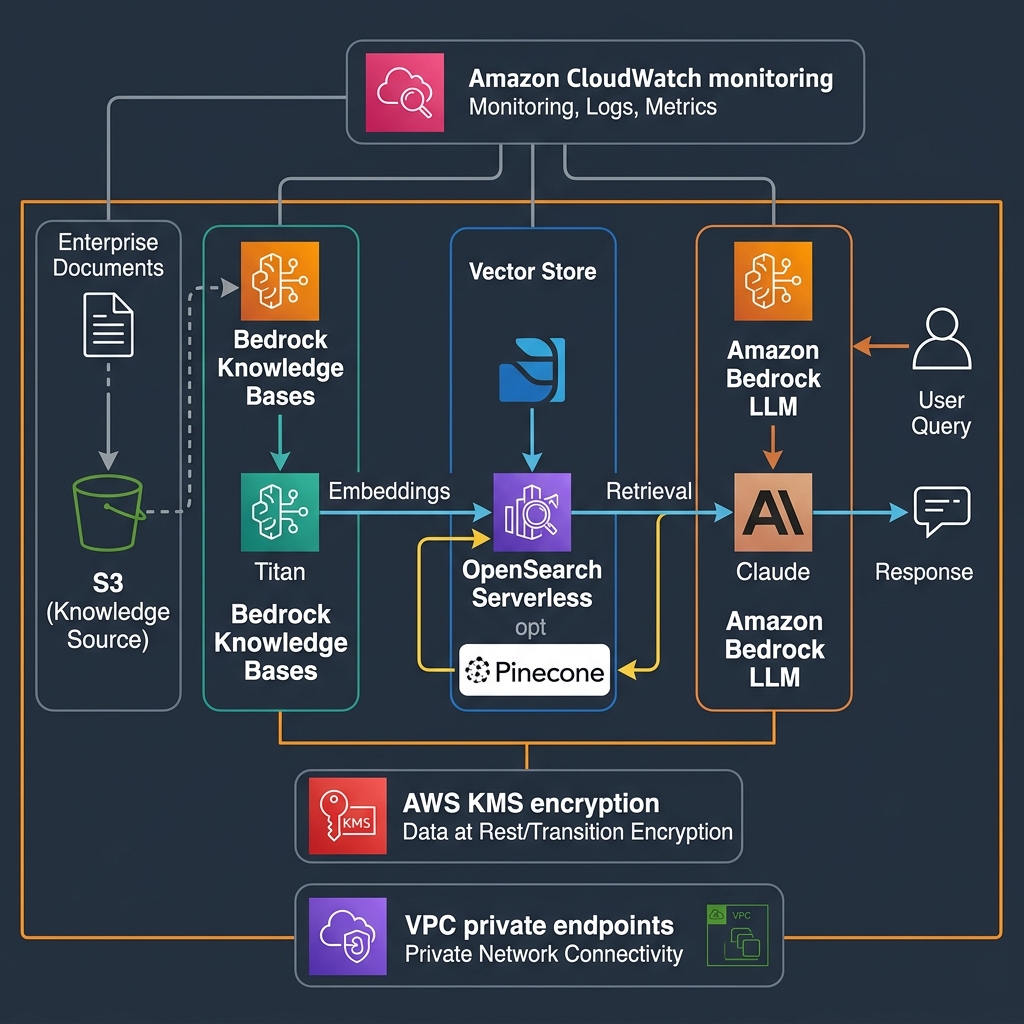
Retrieval Augmented Generation has gone from research novelty to production standard in less than two years. The architecture is well understood: enrich a foundation model’s context window with relevant retrieved documents so it can answer questions grounded in your organisation’s specific knowledge. What has been less well understood is how to do this reliably at production scale.
Bedrock Knowledge Bases removes the hard parts. You point it at an S3 bucket containing your documents — PDFs, Word files, HTML, CSV, Markdown — and it handles chunking strategy, embedding generation using Amazon Titan Embeddings v2 or Cohere Embed, vector storage in OpenSearch Serverless or Pinecone, and retrieval at query time. For a recent enterprise knowledge management project, this reduced our development timeline from three months to three weeks while delivering retrieval accuracy that matched our hand-tuned LangChain implementation. The difference was in production stability: managed Knowledge Bases handles index updates incrementally as new documents arrive, something that is genuinely difficult to implement correctly in DIY RAG pipelines.
import boto3
import json
bedrock_agent = boto3.client("bedrock-agent-runtime", region_name="us-east-1")
def query_knowledge_base(
question: str,
kb_id: str,
model_id: str = "anthropic.claude-3-5-sonnet-20241022-v2:0",
max_results: int = 5
) -> dict:
"""
Query a Bedrock Knowledge Base with semantic retrieval and generation.
Returns both the answer and the source citations.
"""
response = bedrock_agent.retrieve_and_generate(
input={"text": question},
retrieveAndGenerateConfiguration={
"type": "KNOWLEDGE_BASE",
"knowledgeBaseConfiguration": {
"knowledgeBaseId": kb_id,
"modelArn": f"arn:aws:bedrock:us-east-1::foundation-model/{model_id}",
"retrievalConfiguration": {
"vectorSearchConfiguration": {
"numberOfResults": max_results,
"overrideSearchType": "SEMANTIC"
}
},
"generationConfiguration": {
"promptTemplate": {
"textPromptTemplate": (
"You are an expert enterprise assistant. "
"Answer the following question using only the provided context. "
"If the context does not contain the answer, say so clearly.\n\n"
"Context:\n$search_results$\n\n"
"Question: $query$\n\n"
"Provide a precise, technical answer with specific details from the context."
)
}
}
}
}
)
citations = []
for citation in response.get("citations", []):
for ref in citation.get("retrievedReferences", []):
citations.append({
"text": ref["content"]["text"][:200],
"source": ref["location"]["s3Location"]["uri"]
})
return {
"answer": response["output"]["text"],
"citations": citations,
"session_id": response.get("sessionId")
}
Bedrock Agents: Autonomous Multi-Step Task Execution
Beyond RAG, Bedrock Agents enables autonomous task execution. An Agent combines a foundation model with a set of Actions — Lambda functions that the model can invoke — and an optional Knowledge Base for information retrieval. The model reasons about which actions to take, calls them in sequence, observes results, and iterates until the task is complete. This is full agentic AI without managing your own orchestration framework.
In a healthcare document processing pilot, we deployed a Bedrock Agent that could: retrieve patient records from a knowledge base, extract structured data using a Lambda action, validate the extract against business rules in a second action, and route the result to the appropriate downstream system via a third action. The entire orchestration — including retry logic, context management, and tool selection — was managed by Bedrock. Development effort focused entirely on the business logic of each action, not on the orchestration plumbing.
flowchart LR
User["User Query"] --> Agent["Bedrock Agent
(Claude 3.5 Sonnet)"]
Agent --> KB["Knowledge Base
Document Retrieval"]
Agent --> A1["Action: validate-data
(Lambda)"]
Agent --> A2["Action: query-database
(Lambda)"]
Agent --> A3["Action: send-notification
(Lambda)"]
KB --> Agent
A1 --> Agent
A2 --> Agent
A3 --> Response["Final Response
with Citations"]
Agent --> ResponseGuardrails: Enterprise Safety Controls for Production Deployments
No enterprise deployment of generative AI is complete without content safety controls. Bedrock Guardrails provides configurable filtering for harmful content, PII detection and redaction, topic restrictions, and prompt injection detection. Guardrails apply consistently across all foundation models accessed through Bedrock, so you define your safety policy once and it enforces across Claude, Llama, Titan, and every other model in the catalogue.
For healthcare deployments subject to HIPAA, Guardrails’ PII detection can automatically redact PHI from both user inputs and model outputs before logging. For financial services, topic restrictions prevent the model from offering specific investment advice outside its intended scope. The deny-list capability blocks specific terms or content categories at the infrastructure level — independent of the model’s own safety training.
Amazon Q: Purpose-Built AI for the Enterprise
Amazon Q is AWS’s family of purpose-built AI assistants, and it represents a different philosophy from general-purpose foundation model access. Rather than giving you a blank-slate model and asking you to build context from scratch, Q products come pre-loaded with domain knowledge and enterprise integrations that would take months to implement yourself.
Amazon Q Business: Natural Language Access to Organisational Knowledge
Amazon Q Business connects to over 40 enterprise data sources — Salesforce, ServiceNow, Jira, Confluence, SharePoint, S3, databases, ticketing systems, and more — and lets employees query that collective knowledge in natural language. The security model is a first-class feature: Q Business respects the access controls of each underlying data source. An employee asking “what is our Q3 revenue forecast?” only receives information from documents they already have permission to access. This is not a checkbox claim; it is implemented via per-user identity propagation to each connector at retrieval time.
In a large professional services firm deployment, Q Business reduced the average time to find answers to internal policy and process questions from 25 minutes (searching multiple systems manually) to under 90 seconds. The elimination of context-switching between Confluence, SharePoint, Jira, and internal wikis was the primary driver. Secondary value came from Q’s ability to synthesise answers across multiple sources — “What is our data retention policy for healthcare clients and where do I find the template agreement?” — queries that previously required knowing which system held which piece of information.
Amazon Q Developer: AI-Powered Development at Scale
Q Developer has become an essential part of my daily engineering workflow. Unlike generic code assistants that treat cloud infrastructure as just another text corpus, Q Developer has deep AWS semantic understanding. It knows that a Lambda function should not directly invoke another Lambda synchronously for long-running tasks, that DynamoDB single-table design patterns exist and why they matter, and that CloudFormation stacks have specific quotas that affect architectural choices.
The security vulnerability scanning feature deserves specific mention. Q Developer scans Python, Java, JavaScript, TypeScript, C#, Go, Ruby, PHP, Kotlin, and Terraform code for OWASP Top 10 vulnerabilities, AWS security misconfigurations, and exposed secrets. In one engagement, Q Developer identified a hardcoded database connection string in an AWS CDK construct that had been in the codebase for eight months and passed multiple manual code reviews. The static analysis runs in the IDE as you type, not as a separate CI gate.
# Example: Using Amazon Q Developer via CodeWhisperer API for automated security review
import boto3
codewhisperer = boto3.client("codewhisperer", region_name="us-east-1")
def scan_code_for_vulnerabilities(source_code: str, language: str, project_name: str) -> list:
"""
Trigger Amazon Q Developer security scan on source code.
Returns list of findings with severity, CWE, and remediation guidance.
"""
# Create scan job
scan_response = codewhisperer.create_code_scan(
artifacts={
"sourceCode": {
"s3Bucket": "my-security-scans",
"s3Key": f"scans/{project_name}/source.zip"
}
},
programmingLanguage={"languageName": language},
scope="PROJECT",
clientToken=f"{project_name}-{hash(source_code)}"
)
job_id = scan_response["jobId"]
# Poll for completion (simplified - use Step Functions in production)
import time
while True:
status = codewhisperer.get_code_scan(jobId=job_id)["status"]
if status in ("Completed", "Failed"):
break
time.sleep(5)
# Retrieve findings
findings = codewhisperer.list_code_scan_findings(
jobId=job_id,
nextToken=None
)["codeScanFindings"]
return [
{
"severity": f["severity"],
"title": f["title"],
"description": f["description"],
"cwe": f.get("relatedVulnerabilities", []),
"remediation": f["remediation"]["recommendation"]["text"],
"file": f["filePath"],
"line": f["startLine"]
}
for f in findings
if f["severity"] in ("Critical", "High", "Medium")
]
Amazon SageMaker: Custom Model Development and Fine-Tuning
When pre-trained foundation models need domain adaptation, Amazon SageMaker provides the complete toolkit. The choice between fine-tuning and RAG is one of the most consequential decisions in enterprise AI architecture, and the answer depends on what you are trying to achieve.
RAG is the right choice when your use case requires grounding responses in frequently updated documents, when you need citation-level traceability of where answers came from, or when your knowledge corpus changes continuously. Fine-tuning is the right choice when you need the model to adopt a specific style, voice, or format consistently; when you’re adapting a model to a specialised vocabulary or notation (medical imaging reports, financial instruments, legal documents); or when you need the model to reliably refuse certain request patterns regardless of how they are phrased.
Parameter-Efficient Fine-Tuning with SageMaker
Full fine-tuning of large foundation models is computationally expensive and risks catastrophic forgetting of general capabilities. For most enterprise use cases, parameter-efficient fine-tuning (PEFT) methods — particularly LoRA (Low-Rank Adaptation) and QLoRA (Quantized LoRA) — provide 90% of the adaptation benefit at a fraction of the compute cost.
SageMaker JumpStart exposes LoRA fine-tuning for Llama 3, Mistral, and other open-weight models with a few lines of Python. You provide a training dataset in the instruction-tuning format (prompt/completion pairs or chat format), select your hyperparameters, and JumpStart handles distributed training across multiple GPU instances. For a legal document analysis fine-tuning project, we adapted Llama 3 8B on 40,000 annotated contract clauses using QLoRA on a single ml.g5.4xlarge instance in six hours — a task that would have required a cluster of A100 GPUs and two days of engineering time two years ago.
from sagemaker.jumpstart.estimator import JumpStartEstimator
def finetune_llama_on_custom_data(
training_data_s3: str,
output_s3: str,
model_id: str = "meta-textgeneration-llama-3-8b",
instance_type: str = "ml.g5.4xlarge",
epochs: int = 3,
learning_rate: float = 2e-5
):
"""
Fine-tune Llama 3 8B using LoRA via SageMaker JumpStart.
training_data_s3: S3 URI to JSONL file with {"prompt": ..., "completion": ...} records
"""
estimator = JumpStartEstimator(
model_id=model_id,
model_version="*",
instance_type=instance_type,
instance_count=1,
hyperparameters={
"instruction_tuned": "True",
"chat_dataset": "False",
"epoch": str(epochs),
"learning_rate": str(learning_rate),
"lora_r": "16", # LoRA rank - controls adaptation capacity
"lora_alpha": "16", # LoRA scaling factor
"lora_dropout": "0.05",
"per_device_train_batch_size": "4",
"gradient_accumulation_steps": "4",
"max_seq_length": "4096",
"merge_weights": "True" # Merge LoRA weights into base model at end
}
)
estimator.fit({
"training": training_data_s3,
"validation": training_data_s3 # Use same data for demos; split in production
})
# Deploy the fine-tuned model
predictor = estimator.deploy(
initial_instance_count=1,
instance_type="ml.g5.2xlarge",
endpoint_name=f"ft-llama3-legal-{int(__import__('time').time())}"
)
return predictor
SageMaker Model Evaluation and Responsible AI
Deploying a fine-tuned or prompted model to production without rigorous evaluation is one of the most common mistakes I see in enterprise AI projects. SageMaker Model Evaluation provides an automated framework for assessing model quality across accuracy, toxicity, robustness, and bias dimensions using standardised benchmarks and your own custom test sets.
For regulated industries, the evaluation outputs serve a dual purpose: they are inputs to internal quality gates and evidence for regulatory compliance documentation. A healthcare AI system under FDA Software as a Medical Device scrutiny needs documented evidence of model behaviour across demographic subgroups, rare case distributions, and adversarial inputs. SageMaker Model Evaluation can produce these reports automatically from a defined evaluation dataset.
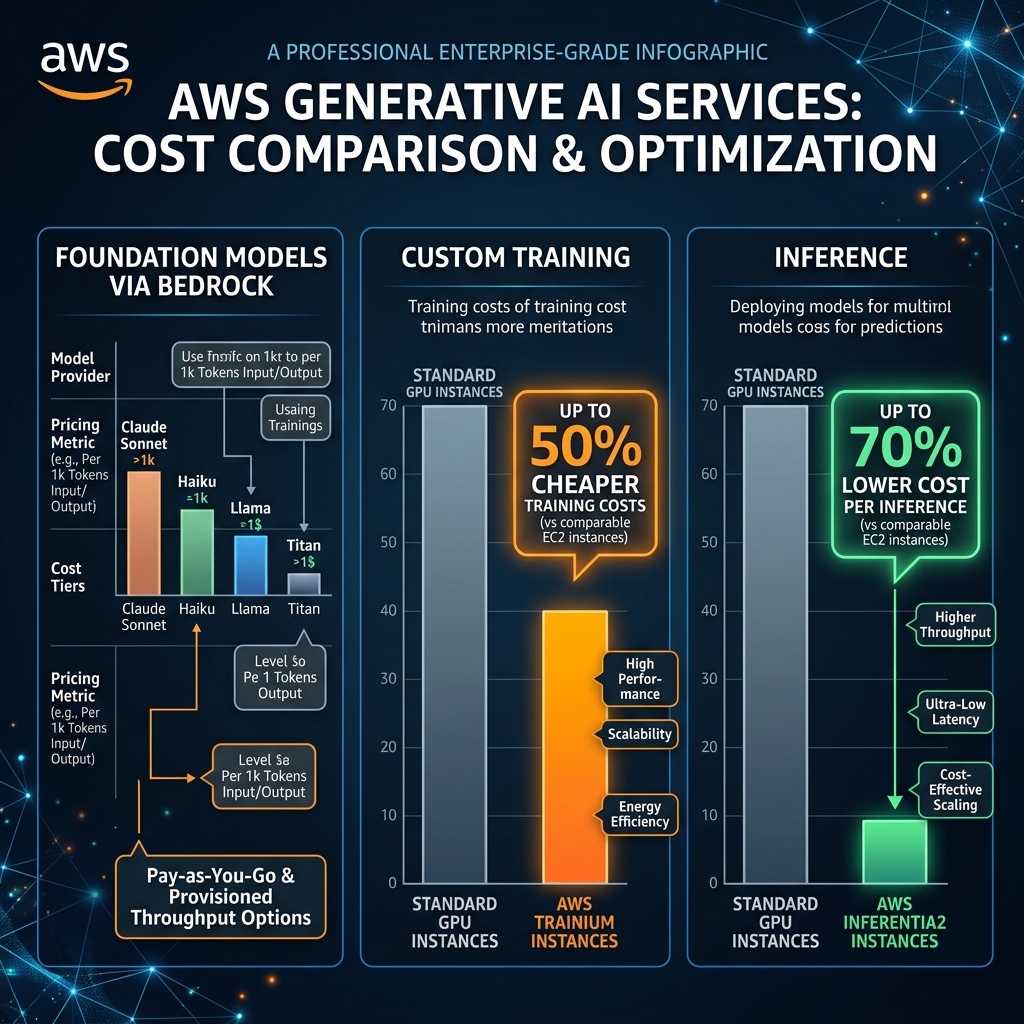
AWS Custom Silicon: Trainium and Inferentia
The hardware economics of generative AI are brutal at scale. Running inference on a Claude 3 Sonnet-equivalent model via Bedrock costs $3/$15 per million tokens (input/output). For a high-volume enterprise application processing millions of daily queries, those costs compound rapidly. AWS’s custom silicon — Trainium for training and Inferentia for inference — exists to address this at the infrastructure layer.
AWS Trainium2 chips, available in the Trn2 instance family, deliver up to 50% cost savings compared to GPU instances for training equivalent model sizes. The comparison is most compelling for training workloads that run continuously — pre-training, continued pre-training on domain-specific corpora, or large-scale RLHF. For fine-tuning runs that complete in hours on a single instance, the difference is less significant and GPU availability and ecosystem tooling often dominate the decision.
AWS Inferentia2, available in Inf2 instances, is purpose-built for inference cost reduction. The chip architecture optimises for the memory bandwidth requirements of autoregressive LLM inference — the step-by-step token generation that makes LLM serving uniquely demanding. In production deployments I have measured, routing inference through Inf2 instances via SageMaker endpoints achieves 30-70% cost reduction compared to equivalent GPU instances, with comparable or better latency for batch sizes from 1 to 64 concurrent requests.
flowchart LR
subgraph Training ["Model Training Workloads"]
T1["Pre-training
Trn2 instances
50% cheaper vs GPU"]
T2["Fine-tuning
ml.g5 or Trn1
LoRA reduces cost 10x"]
T3["RLHF
Trn2 + SageMaker
Distributed training"]
end
subgraph Inference ["Production Inference"]
I1["High-Volume API
Inf2 instances
60% cheaper vs A10G"]
I2["Real-time Endpoints
G5 / A10G
Lowest latency"]
I3["Batch Transform
CPU or Trn1
Highest throughput/cost"]
end
Training --> InferenceProduction Architecture Patterns That Actually Work
After deploying generative AI systems across multiple enterprises spanning healthcare, financial services, and retail, several architectural patterns have proven consistently reliable. These are not theoretical — they represent lessons from production systems handling millions of daily requests.
Multi-Model Router Pattern
A single foundation model is rarely optimal for every query in a production system. A customer support application might receive questions that range from simple FAQ lookups (best served by Claude Haiku at $0.25/million tokens) to complex billing disputes requiring multi-step reasoning (better served by Claude Sonnet at $3/million tokens). Routing queries to the appropriate model based on complexity, expected output length, and sensitivity can reduce per-request costs by 40-60% without degrading quality for complex queries.
import boto3
import json
bedrock = boto3.client("bedrock-runtime", region_name="us-east-1")
MODEL_COSTS = {
"amazon.nova-micro-v1:0": {"input": 0.000035, "output": 0.00014},
"anthropic.claude-3-haiku-20240307-v1:0": {"input": 0.00025, "output": 0.00125},
"anthropic.claude-3-5-sonnet-20241022-v2:0": {"input": 0.003, "output": 0.015},
}
def classify_query_complexity(query: str) -> str:
"""
Route to appropriate model based on query complexity.
Uses Nova Micro as cheap classifier to avoid expensive model for simple queries.
"""
classification_prompt = (
f"Classify this customer query into: SIMPLE (FAQ, factual), "
f"MEDIUM (multi-step, calculation), or COMPLEX (legal, dispute, edge case).
"
f"Query: {query}
Respond with only: SIMPLE, MEDIUM, or COMPLEX"
)
response = bedrock.invoke_model(
modelId="amazon.nova-micro-v1:0",
body=json.dumps({
"messages": [{"role": "user", "content": classification_prompt}],
"inferenceConfig": {"maxTokens": 10, "temperature": 0}
})
)
return json.loads(response["body"].read())["output"]["message"]["content"][0]["text"].strip()
def route_and_respond(query: str, context: str) -> dict:
complexity = classify_query_complexity(query)
model_routing = {
"SIMPLE": "amazon.nova-micro-v1:0",
"MEDIUM": "anthropic.claude-3-haiku-20240307-v1:0",
"COMPLEX": "anthropic.claude-3-5-sonnet-20241022-v2:0",
}
selected_model = model_routing[complexity]
prompt = f"Context: {context}
Query: {query}"
response = bedrock.invoke_model(
modelId=selected_model,
body=json.dumps({
"messages": [{"role": "user", "content": prompt}],
"max_tokens": 1024,
"anthropic_version": "bedrock-2023-05-31"
})
)
return {
"answer": json.loads(response["body"].read())["content"][0]["text"],
"model_used": selected_model,
"complexity": complexity
}
Observability: Logging, Tracing, and Cost Attribution
Generative AI systems fail in ways that traditional software does not. A model can produce a factually incorrect response that passes all automated checks and only surfaces through user feedback. An inference spike can occur when a batch of complex queries arrives simultaneously, exceeding rate limits and causing cascading failures. These failure modes require observability infrastructure that captures more than just HTTP status codes.
Implement CloudWatch structured logging for every Bedrock API call, capturing: model ID, input token count, output token count, latency, response finish reason (stop vs max tokens), and a hash of the input for privacy-safe deduplication. Use X-Ray to trace requests across the full stack — API Gateway, Lambda, Bedrock, Knowledge Base retrieval, and any downstream services. Tag every Bedrock API call with a cost allocation tag linking it to the business unit, application, and use case, enabling per-feature AI cost reporting in AWS Cost Explorer.
bedrock:InvokeModel token consumption metrics, split by model ID. Alert at 80% of your daily token budget. Use AWS Budgets actions to automatically invoke a Lambda that switches to a cheaper model or enables request queuing when budgets are exceeded. This prevents runaway costs from usage spikes without requiring manual intervention.Rate Limiting and Quota Management
Bedrock model quotas (tokens per minute, requests per minute) are soft limits that can be increased but not eliminated. In production systems serving multiple applications or tenants, implement an API Gateway with a Lambda rate limiter that distributes the available quota across consumers according to business priority. Use SQS with a Bedrock consumer Lambda as a buffer for non-latency-sensitive workloads, allowing them to absorb burst without exhausting quota that real-time applications need.
Compliance and Data Governance in Enterprise AI
Enterprise adoption of generative AI is often gated on compliance questions rather than technical ones. The good news: AWS has invested heavily in making Bedrock and its surrounding services compliance-ready.
Data stays in your account: When you invoke a foundation model through Bedrock, your prompts and responses are not used to train the underlying model. AWS contractually confirms this in the Bedrock service terms. For healthcare and financial services customers under strict data handling obligations, this is the baseline requirement that makes Bedrock usable rather than a proof-of-concept toy.
VPC private endpoints: Bedrock supports AWS PrivateLink, allowing you to route all model invocations through VPC endpoints without traffic traversing the public internet. Combined with restrictive security group rules and VPC endpoint policies, this creates a network perimeter around AI inference that satisfies many regulatory network segmentation requirements.
Audit logging: All Bedrock API calls (including individual model invocations) are logged in AWS CloudTrail. For SOC 2, PCI-DSS, and HIPAA compliance, CloudTrail provides the authoritative audit trail of who called which model, when, from which principal, and with what resource-level permissions.
Key Takeaways
- Amazon Bedrock provides the unified API foundation for accessing 30+ foundation models with built-in Knowledge Bases (managed RAG), Agents (autonomous task execution), and Guardrails (safety controls) — this is the starting point for 90% of enterprise AI application development
- Model selection is a continuous decision, not a one-time choice: route different query types to different models based on complexity and cost, and revisit routing as new models enter the catalogue
- Amazon Q Business and Q Developer represent the fastest path to measurable enterprise value — Q Business for organisational knowledge retrieval and Q Developer for engineering velocity and security scanning
- SageMaker fine-tuning with LoRA/QLoRA is now accessible to application development teams, not just ML specialists — favour parameter-efficient methods and evaluate rigorously before production deployment
- Custom silicon (Trainium2, Inferentia2) delivers 30-70% inference cost reduction for high-volume workloads; the break-even point is typically above 10 million tokens/day where the infrastructure savings exceed engineering overhead
- Production discipline — comprehensive observability, cost attribution, rate limiting, and compliance documentation — separates successful enterprise AI deployments from expensive experiments that never reach scale
Discover more from C4: Container, Code, Cloud & Context
Subscribe to get the latest posts sent to your email.