After two decades of architecting data systems across financial services, healthcare, and e-commerce, I’ve witnessed the evolution from batch-only processing to today’s sophisticated real-time architectures. The shift isn’t just about speed—it’s about fundamentally changing how organizations make decisions and respond to events. This article shares battle-tested insights on building production-grade real-time data processing systems in modern cloud environments.
The Real-Time Imperative
Real-time data processing has moved from “nice-to-have” to “business-critical” across virtually every industry. When I started building data pipelines in the early 2000s, a 24-hour batch window was acceptable. Today, millisecond latencies determine competitive advantage in trading systems, fraud detection, and customer experience platforms.
The distinction between true real-time (sub-second latency) and near real-time (seconds to minutes) matters significantly in architecture decisions. True streaming processes each event individually as it arrives, while micro-batch approaches collect events over small windows before processing. Each has its place, and understanding when to use which approach separates successful implementations from costly failures.
Architecture Patterns: Lambda vs. Kappa
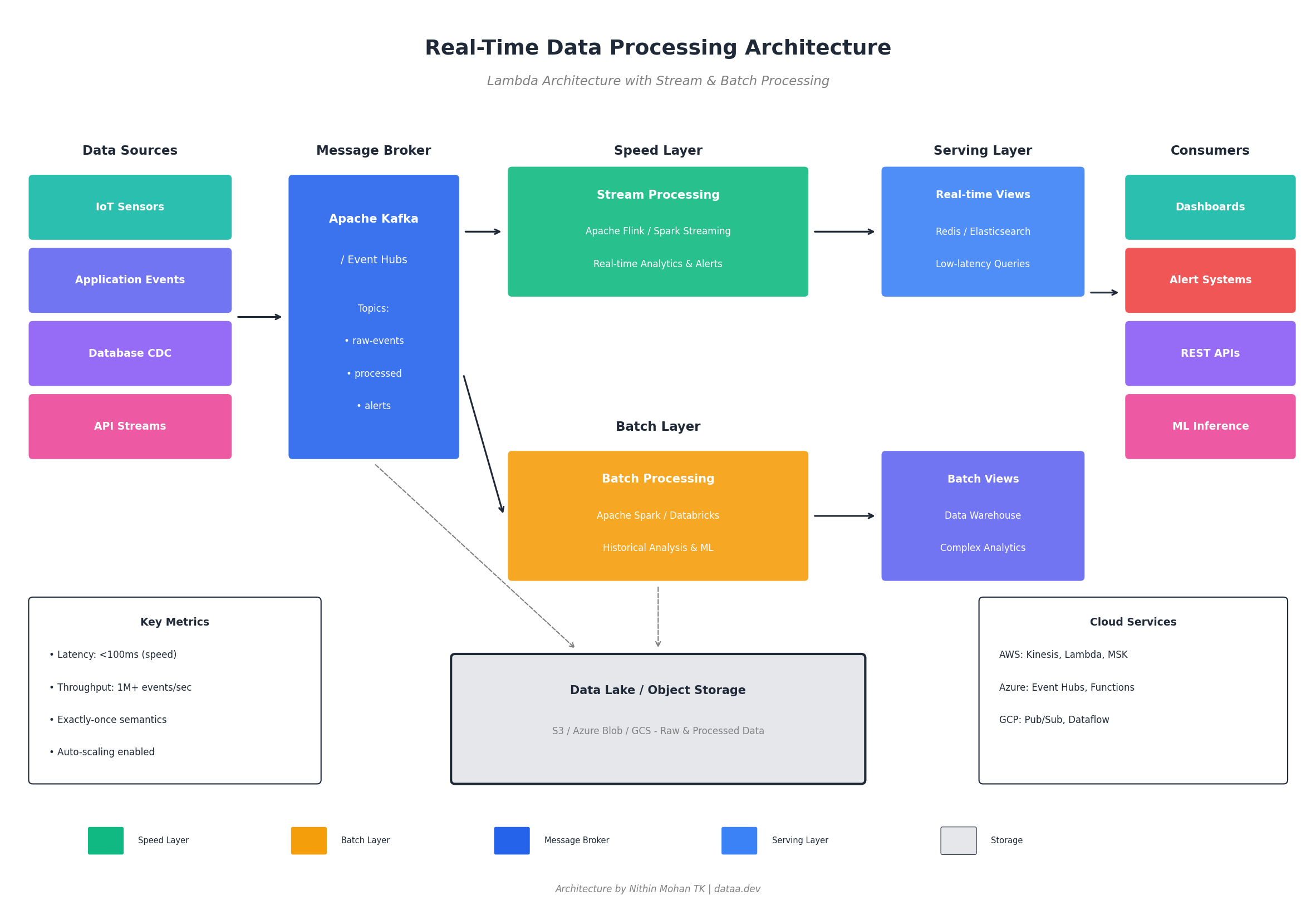
The two dominant architectural patterns for real-time processing are Lambda and Kappa architectures. Having implemented both in production environments, I can share practical guidance on when each excels.
Lambda Architecture
Lambda Architecture maintains parallel batch and speed layers, merging results in a serving layer. The batch layer provides accuracy through complete reprocessing, while the speed layer delivers low-latency approximate results. This pattern works exceptionally well when you need both real-time insights and guaranteed accuracy for historical analysis.
I’ve deployed Lambda architectures successfully in financial reconciliation systems where real-time position tracking must eventually reconcile with authoritative batch calculations. The complexity of maintaining two codebases (batch and streaming) is justified when regulatory requirements demand provable accuracy alongside real-time visibility.
Kappa Architecture
Kappa Architecture simplifies by treating everything as a stream, including historical reprocessing. When you need to fix a bug or update business logic, you replay the event log through the updated streaming job. This approach reduces operational complexity significantly but requires robust event sourcing and replay capabilities.
For most modern applications, I recommend starting with Kappa unless you have specific requirements that mandate Lambda’s dual-path approach. The operational simplicity of maintaining a single processing paradigm typically outweighs Lambda’s theoretical advantages.
When to Use What: Stream Processing Technology Selection
Choosing the right stream processing technology is one of the most consequential architectural decisions you’ll make. Here’s my framework based on implementing these technologies across dozens of production systems.
Apache Kafka
Best for: Event streaming backbone, message broker, event sourcing, log aggregation
Cost Efficiency: Excellent for high-throughput scenarios. Self-managed Kafka on commodity hardware handles millions of messages per second. Confluent Cloud pricing scales with throughput but can become expensive at very high volumes.
Ease of Use: Moderate learning curve. Kafka itself is straightforward, but the ecosystem (Connect, Streams, Schema Registry) requires investment to master. Operational complexity is significant for self-managed deployments.
Scalability: Exceptional horizontal scalability through partitioning. I’ve operated clusters handling 2+ million messages per second with proper partition strategies.
When to choose: When you need a durable, replayable event log as the foundation of your data architecture. Kafka excels as the “central nervous system” connecting microservices and feeding downstream analytics.
Apache Flink
Best for: Complex event processing, stateful stream processing, exactly-once semantics, low-latency analytics
Cost Efficiency: Higher infrastructure requirements than simpler alternatives due to state management overhead. However, the ability to handle complex processing in a single job often reduces overall system cost compared to chaining multiple simpler tools.
Ease of Use: Steeper learning curve, especially for stateful processing and windowing semantics. The DataStream and Table APIs require understanding of watermarks, event time, and state backends.
Scalability: Excellent scalability with sophisticated state management. Flink’s incremental checkpointing enables scaling stateful applications that would be impossible with other frameworks.
When to choose: When you need true event-time processing, complex windowing, or exactly-once guarantees. Flink is my go-to for fraud detection, real-time ML feature engineering, and any scenario requiring sophisticated stateful logic.
Apache Spark Structured Streaming
Best for: Unified batch and streaming, ML pipeline integration, teams already using Spark for batch processing
Cost Efficiency: Good for organizations already invested in Spark infrastructure. The micro-batch model can be more resource-efficient for near real-time use cases where sub-second latency isn’t required.
Ease of Use: Excellent if your team knows Spark. The DataFrame/Dataset API provides a familiar programming model. Continuous processing mode (true streaming) is less mature than micro-batch.
Scalability: Leverages Spark’s proven distributed computing model. Scales well but with higher latency floor than Flink due to micro-batch architecture.
When to choose: When you need unified batch and streaming pipelines, especially for ML workflows. If your team is Spark-native and latency requirements are seconds rather than milliseconds, Structured Streaming is often the pragmatic choice.
Amazon Kinesis
Best for: AWS-native architectures, serverless streaming, quick time-to-market
Cost Efficiency: Pay-per-shard pricing can be expensive at scale compared to self-managed Kafka. However, zero operational overhead makes TCO favorable for smaller to medium workloads.
Ease of Use: Excellent. Fully managed with tight AWS integration. Kinesis Data Analytics provides SQL-based stream processing without infrastructure management.
Scalability: Good but with shard limits that require planning. Each shard handles 1MB/sec input and 2MB/sec output. Resharding operations can be disruptive.
When to choose: When you’re all-in on AWS and want minimal operational burden. Kinesis + Lambda + DynamoDB provides a powerful serverless streaming stack for many use cases.
Azure Event Hubs + Stream Analytics
Best for: Azure-native architectures, IoT scenarios, SQL-familiar teams
Cost Efficiency: Throughput unit pricing is predictable. Stream Analytics jobs are priced by streaming units, which can be cost-effective for moderate complexity queries.
Ease of Use: Stream Analytics’ SQL-like query language dramatically lowers the barrier to entry. Event Hubs integrates seamlessly with Azure services.
Scalability: Event Hubs scales well with throughput units. Stream Analytics auto-scales but complex jobs may require careful streaming unit allocation.
When to choose: Azure-centric organizations, especially those with IoT workloads. The integration with Azure IoT Hub, Cosmos DB, and Power BI creates a compelling end-to-end platform.
Google Cloud Dataflow
Best for: Apache Beam workloads, unified batch/streaming, GCP-native architectures
Cost Efficiency: Autoscaling optimizes resource usage automatically. Pricing based on vCPU, memory, and data processed. Can be expensive for always-on streaming jobs but efficient for variable workloads.
Ease of Use: Apache Beam’s programming model has a learning curve, but Dataflow’s managed infrastructure eliminates operational complexity. Templates enable no-code deployment of common patterns.
Scalability: Excellent automatic scaling based on backlog. Dataflow dynamically adjusts workers without manual intervention.
When to choose: When you want portability (Beam runs on multiple runners) or need sophisticated windowing and triggering semantics. Dataflow excels at complex event-time processing with automatic scaling.
Decision Matrix: Choosing Your Stack
| Scenario | Recommended Stack | Rationale |
|---|---|---|
| Startup, AWS-native, quick MVP | Kinesis + Lambda | Minimal ops, fast iteration, scales with business |
| Enterprise, multi-cloud, complex processing | Kafka + Flink | Maximum flexibility, best-in-class capabilities |
| Data science team, ML pipelines | Kafka + Spark Streaming | Unified batch/streaming, familiar APIs |
| Azure shop, IoT focus | Event Hubs + Stream Analytics | Native integration, SQL simplicity |
| GCP, variable workloads | Pub/Sub + Dataflow | Autoscaling, Beam portability |
| Cost-sensitive, high volume | Self-managed Kafka + Flink | Best price/performance at scale |
| Regulatory, exactly-once required | Kafka + Flink | Strongest exactly-once guarantees |
Production Best Practices
Beyond technology selection, successful real-time systems require attention to operational concerns that often determine production success or failure.
Exactly-Once Semantics
True exactly-once processing requires coordination between your streaming framework, message broker, and sink systems. Kafka’s transactional producers combined with Flink’s two-phase commit sinks provide the strongest guarantees, but at a performance cost. For many use cases, idempotent processing with at-least-once delivery is simpler and sufficient.
Backpressure Handling
Production systems must gracefully handle traffic spikes. Implement backpressure mechanisms that slow ingestion rather than dropping data or crashing. Kafka’s consumer lag monitoring and Flink’s backpressure metrics are essential operational signals.
State Management
Stateful stream processing introduces complexity around checkpointing, recovery, and state size management. Use incremental checkpointing for large state, implement TTL policies to prevent unbounded state growth, and test recovery scenarios regularly.
Schema Evolution
Real-time systems must handle schema changes without downtime. Implement schema registries (Confluent Schema Registry, AWS Glue Schema Registry) with compatibility rules. Design schemas for forward and backward compatibility from day one.
Implementation Example: Real-Time Fraud Detection
Here’s a production pattern I’ve implemented for real-time fraud detection using Flink:
// Flink fraud detection with stateful processing
public class FraudDetector extends KeyedProcessFunction<String, Transaction, Alert> {
private ValueState<Double> rollingSum;
private ValueState<Long> transactionCount;
@Override
public void processElement(Transaction tx, Context ctx, Collector<Alert> out) {
// Update rolling statistics
double currentSum = rollingSum.value() + tx.getAmount();
long currentCount = transactionCount.value() + 1;
// Velocity check: too many transactions in window
if (currentCount > VELOCITY_THRESHOLD) {
out.collect(new Alert(tx.getUserId(), "VELOCITY_EXCEEDED", tx));
}
// Amount anomaly: deviation from user's normal pattern
double avgAmount = currentSum / currentCount;
if (tx.getAmount() > avgAmount * ANOMALY_MULTIPLIER) {
out.collect(new Alert(tx.getUserId(), "AMOUNT_ANOMALY", tx));
}
// Register timer for window expiration
ctx.timerService().registerEventTimeTimer(
ctx.timestamp() + WINDOW_DURATION_MS
);
rollingSum.update(currentSum);
transactionCount.update(currentCount);
}
}Conclusion
Real-time data processing has matured from experimental technology to essential infrastructure. The key to success lies not in choosing the “best” technology, but in matching capabilities to requirements: latency needs, processing complexity, operational capacity, and existing ecosystem investments.
Start with clear requirements, prototype with managed services to validate assumptions, and invest in operational excellence as you scale. The streaming landscape continues to evolve rapidly, but the architectural principles—event-driven design, idempotent processing, and graceful degradation—remain constant foundations for building systems that deliver real-time value.
Discover more from C4: Container, Code, Cloud & Context
Subscribe to get the latest posts sent to your email.