
The journey from experimental machine learning models to production-grade systems represents one of the most challenging transitions in modern software engineering. After spending two decades building distributed systems and watching countless ML projects struggle to move beyond proof-of-concept, I’ve developed a deep appreciation for cloud-native approaches that treat machine learning infrastructure with the same rigor we apply to traditional software systems.
The Production Reality Gap
Most data science teams can build impressive models in Jupyter notebooks. The challenge emerges when those models need to serve millions of predictions per day, handle traffic spikes gracefully, recover from failures automatically, and maintain consistent performance as data distributions shift over time. This gap between experimental success and production reliability is where cloud-native principles become essential.
Cloud-native machine learning isn’t simply about deploying models to cloud infrastructure. It’s about designing ML systems that embrace the principles of containerization, microservices architecture, declarative configuration, and continuous delivery. These principles, when applied thoughtfully to machine learning workflows, create systems that are resilient, scalable, and maintainable over the long term.
Architecture Patterns That Actually Work
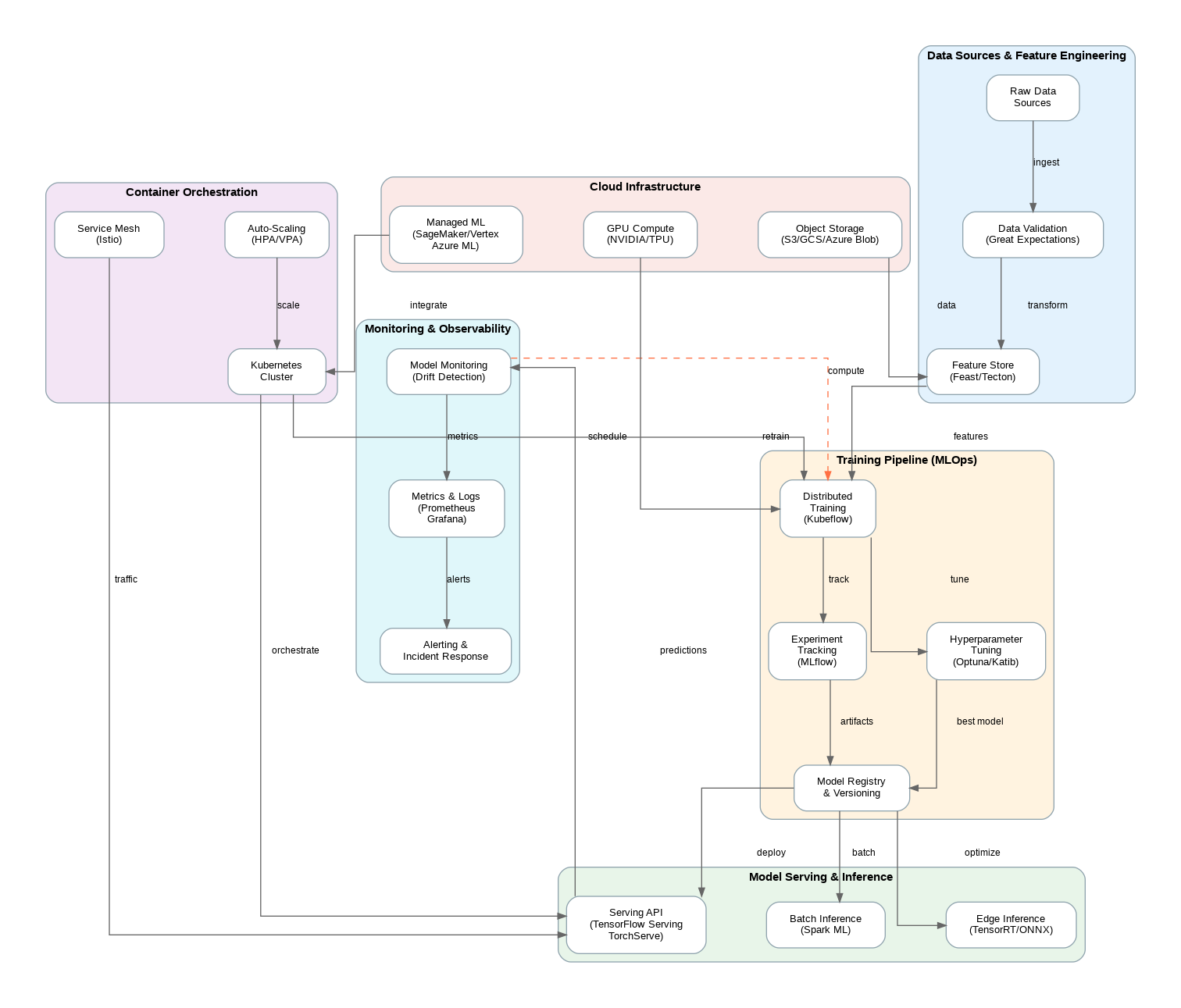
The architecture diagram above illustrates the key components of a production-ready cloud-native ML system. Let me walk through each layer and share lessons learned from implementing these patterns across various organizations.
The Data Sources and Feature Engineering layer forms the foundation. Raw data flows through validation pipelines into a centralized feature store. This pattern solves one of the most persistent problems in ML systems: feature consistency between training and inference. When your training pipeline computes features differently than your serving pipeline, you get training-serving skew that silently degrades model performance. A well-designed feature store eliminates this class of bugs entirely.
The Training Pipeline layer handles the iterative process of model development. Experiment tracking systems like MLflow or Weights & Biases capture every training run’s parameters, metrics, and artifacts. Distributed training frameworks enable scaling to larger datasets and more complex models. Hyperparameter tuning services automate the search for optimal configurations. The model registry provides versioned storage with metadata about each model’s lineage and performance characteristics.
The Model Serving and Inference layer is where models meet production traffic. This layer must handle real-time API requests with low latency, batch inference jobs for offline predictions, and increasingly, edge deployment for scenarios requiring local inference. Each serving pattern has different requirements for latency, throughput, and resource utilization.
Kubernetes as the Foundation
Container orchestration through Kubernetes has become the de facto standard for cloud-native ML deployments. The platform provides auto-scaling based on custom metrics like inference latency or queue depth, service mesh capabilities for traffic management and observability, and declarative configuration that enables GitOps workflows for ML infrastructure.
I’ve seen teams struggle when they treat Kubernetes as simply a deployment target rather than embracing its full capabilities. The real power comes from using custom resources and operators to encode ML-specific concepts like training jobs, model deployments, and A/B tests as first-class Kubernetes objects. Tools like Kubeflow, Seldon Core, and KServe provide these abstractions out of the box.
Monitoring and Observability
Production ML systems require monitoring at multiple levels. Infrastructure metrics track resource utilization and system health. Application metrics measure request latency, throughput, and error rates. Model metrics monitor prediction distributions, feature drift, and performance degradation over time.
The most insidious failures in ML systems are silent. A model can continue serving predictions while its accuracy degrades due to data drift. Effective monitoring requires establishing baselines during model validation and continuously comparing production behavior against those baselines. Alerting systems should trigger when statistical properties of predictions or input features deviate significantly from expected distributions.
Lessons from Production Deployments
Several patterns have proven valuable across the production ML systems I’ve helped build. First, treat model deployment as a software release process with staged rollouts, canary deployments, and automated rollback capabilities. Second, invest heavily in data validation at every stage of the pipeline. Third, design for failure by implementing circuit breakers, fallback models, and graceful degradation strategies.
The cloud providers offer managed services that can accelerate adoption of these patterns. AWS SageMaker, Google Vertex AI, and Azure Machine Learning each provide integrated platforms covering the full ML lifecycle. These services reduce operational burden but require careful evaluation of vendor lock-in implications and cost structures at scale.
Looking Forward
Cloud-native machine learning continues to evolve rapidly. Emerging patterns around foundation models, vector databases for retrieval-augmented generation, and edge ML deployment are reshaping how we think about production ML architecture. The fundamental principles of scalability, reliability, and maintainability remain constant even as the specific technologies change.
Building production ML systems requires combining deep understanding of machine learning with solid software engineering practices. The cloud-native approach provides a proven framework for bridging this gap, enabling organizations to move from experimental models to reliable production systems that deliver real business value.
Discover more from C4: Container, Code, Cloud & Context
Subscribe to get the latest posts sent to your email.